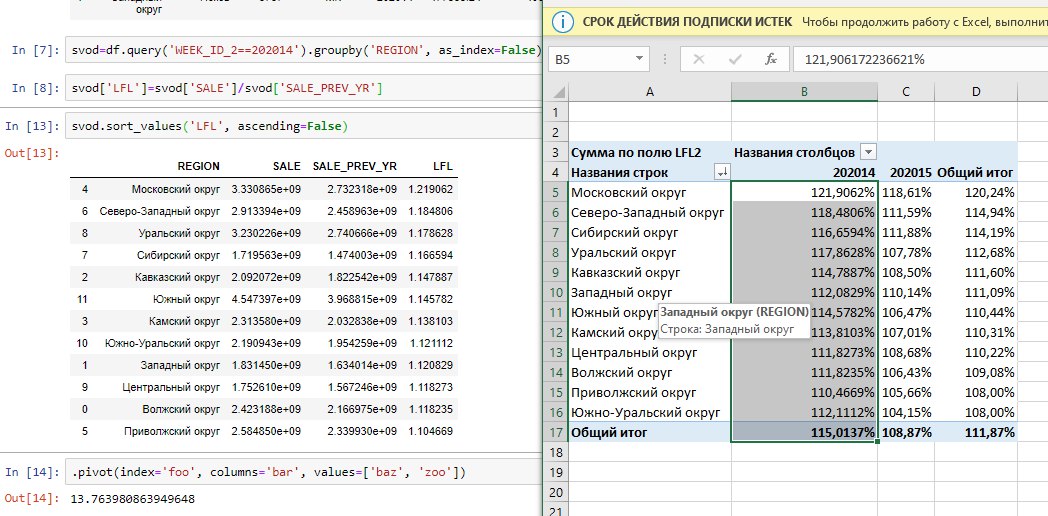
import pandas as pd
import numpy as np
df = pd.read_excel('magnit.xlsx', sheet_name='Данные')
df_result = df.pivot_table(index=['REGION'],
values=['SALE', 'SALE_PREV_YR'],
columns='WEEK_ID_2', aggfunc=np.sum).reset_index()
df_result.columns = [
'REGION',
'SALE_202014',
'SALE_202015',
'SALE_PREV_YR_202014',
'SALE_PREV_YR_202015']
df_result['lfl_sale_202014'] = (df_result['SALE_202014'] / df_result['SALE_PREV_YR_202014'])
df_result.sort_values('lfl_sale_202014', ascending=False)