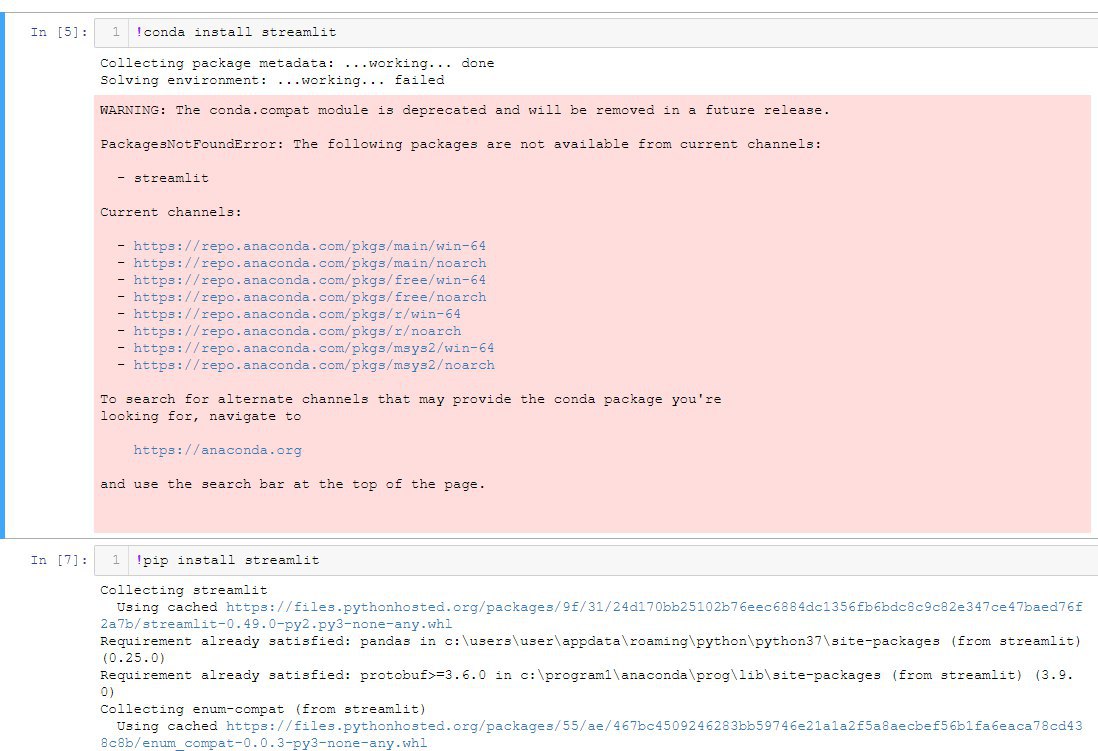
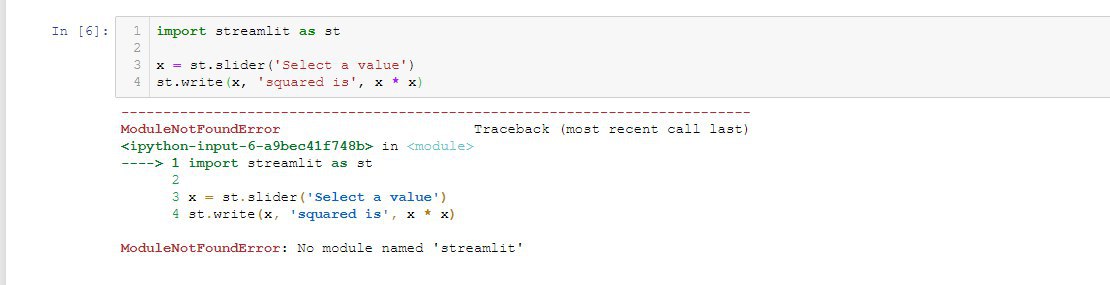
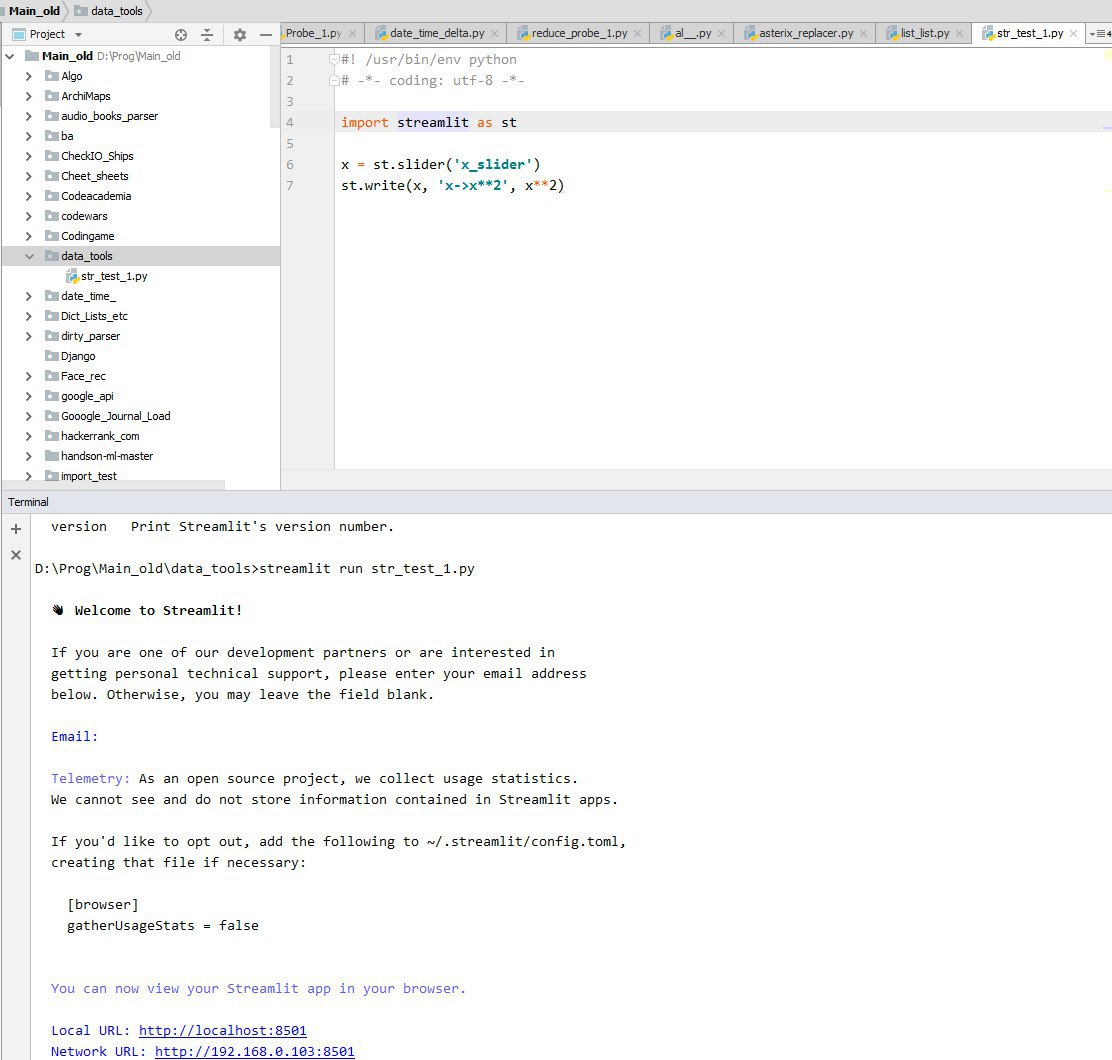
I
это понятно, вот и хочу попросить помочь определить минимальное расстояние, оно какое? как определить? где-то оно больше, где-то меньше...
Проходим итерацию сопоставления, записываем данные расстояние в словарь "регион":"расстояние", выбираем ключ с минимальным значением, записываем значение ключа как регион в таблицу.
Это имелось в виду?
Это имелось в виду?