



AM
Пивотом можно попробовать)
Size: a a a
AM
PZ
А
А
А
А
PZ
PZ
А
VM
import pandas as pd
data = [['sasha', 'male', 1, 0, 1, 2, 2, 1, 3, 2],
['oleg', 'male', 2, 1, 4, 5, 2, 1, 4, 2]]
df = pd.DataFrame(data)
df.columns = [f'col_{i}' for i in range(df.shape[1])]
print(df)
df2 = pd.melt(df, ['col_0', 'col_1'])
print(df2)
П
m
3
m
А

А
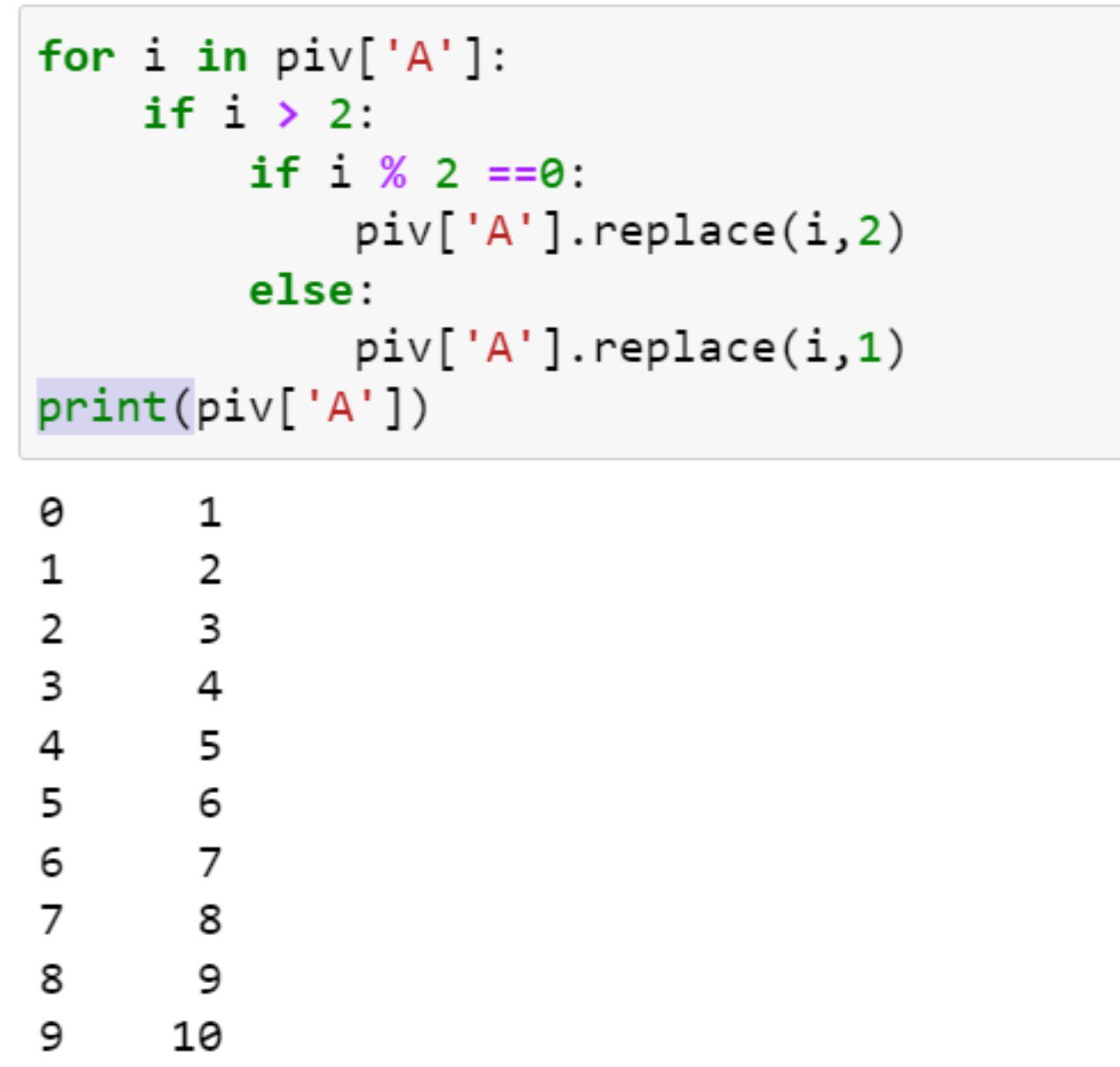
3
3
VF
piv["B"] = piv["B"].replace({"План" : 1, "Факт" : 2})m
piv[piv['B'] == "План"]]["A"] = 1
piv[piv['B'] == "Факт"]]["A"] = 2