h
мне кажется, что что-то не то.
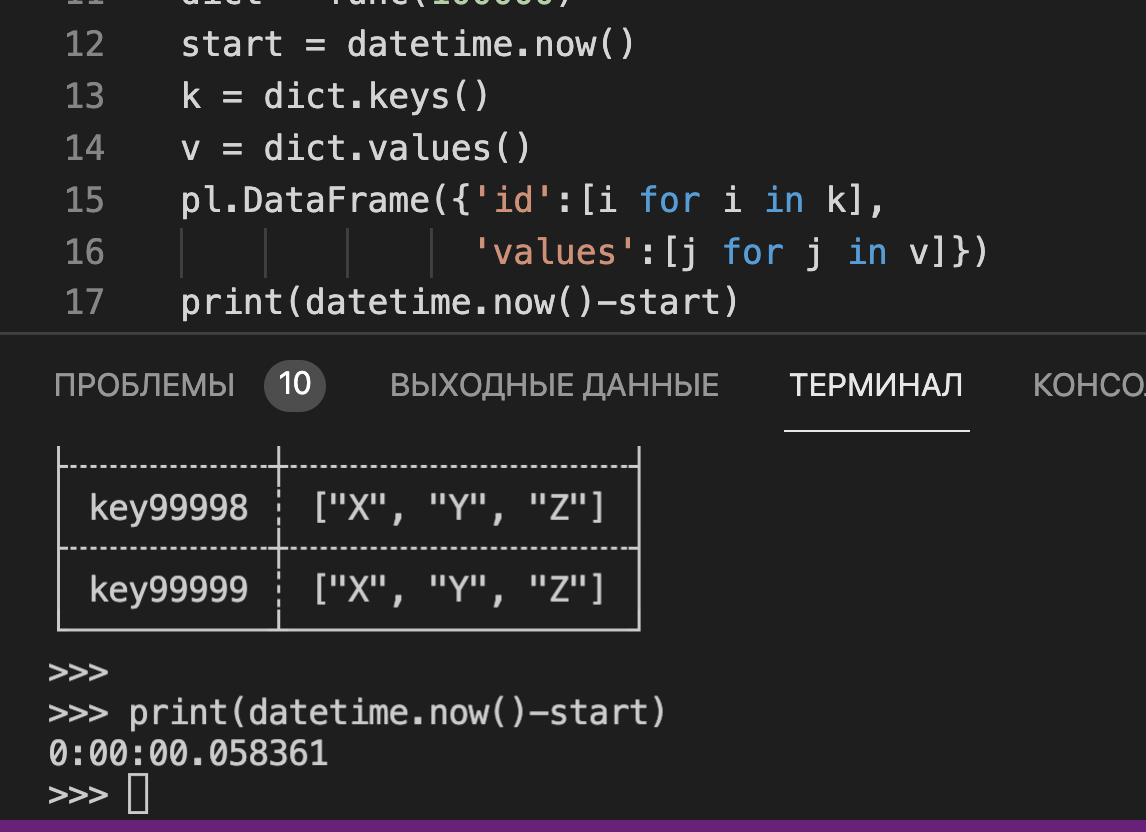
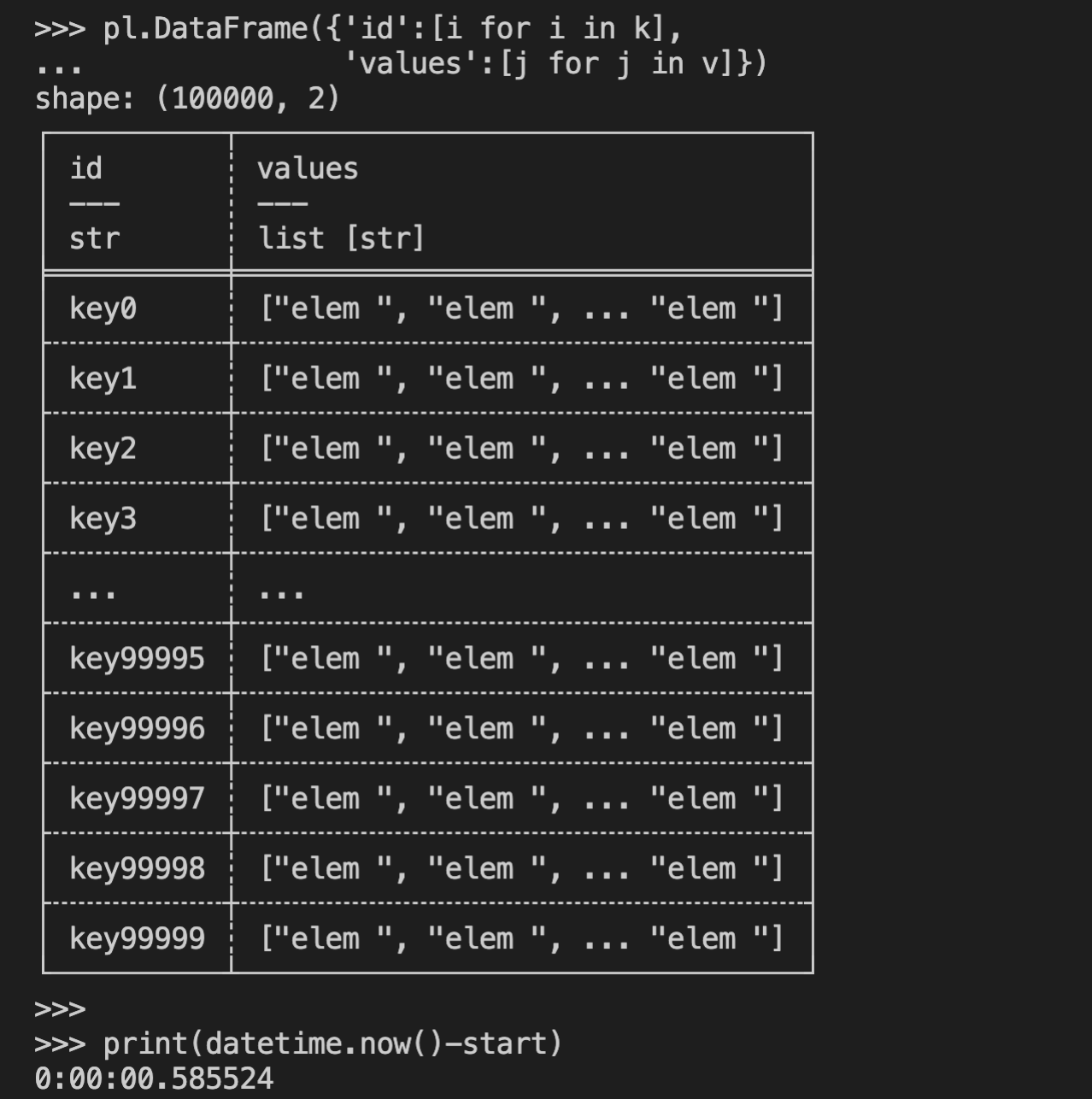
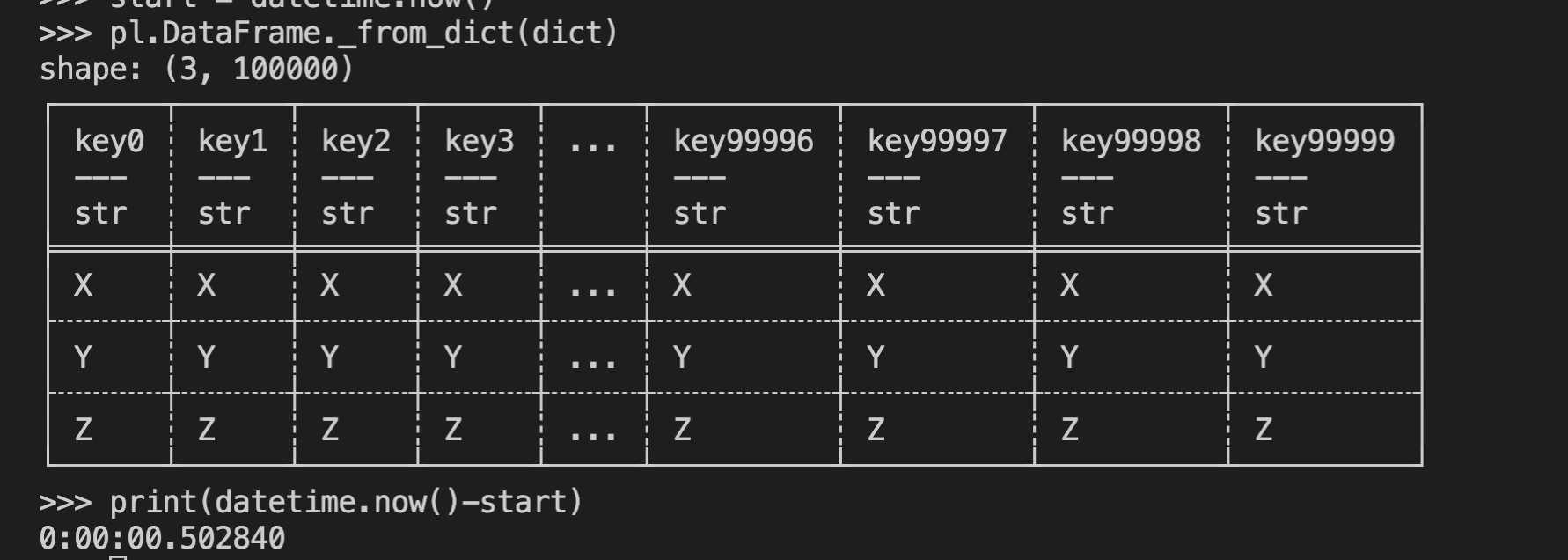
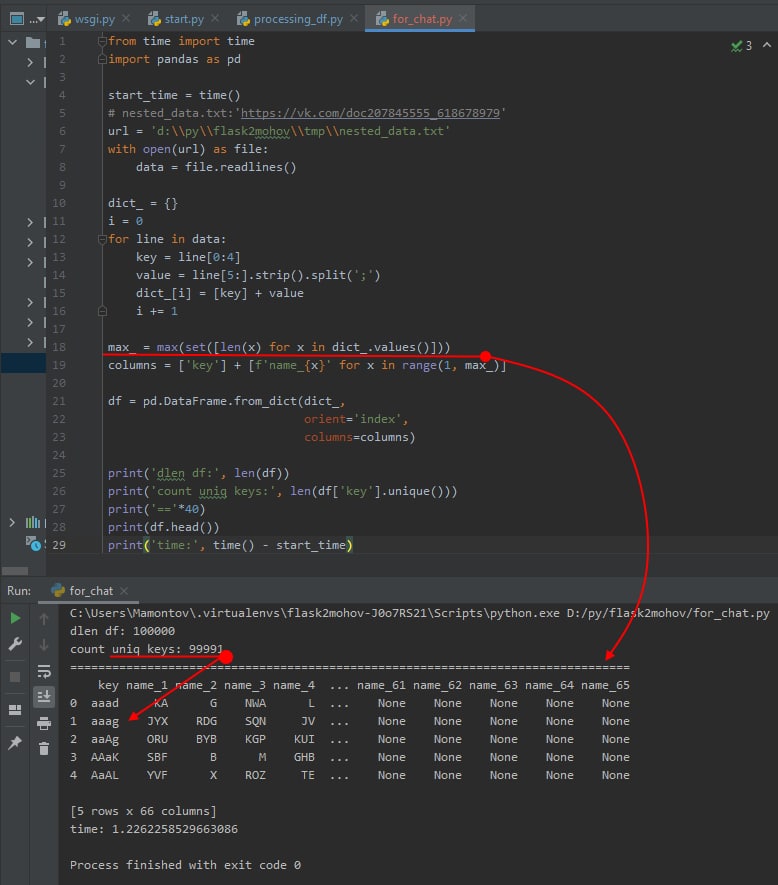
две колонки надо: id и var, длинное представление.
а тут те же 0.5 секунды получаются?
Size: a a a
IS
h
IS
IS
h
h

h
E
AG
EZ
df = json_normalize(test)
pallet = pd.DataFrame(columns = ["sscc","packing_date","owner_id","owner_organization_name","childs"])
pachka = pd.DataFrame(columns = ["sgtin","sscc","status","gtin","expiration_date","batch","pallet"])
for i in range(len(json_normalize(test))):
sscc = json_normalize(test[i]["down"])
pallet = pd.concat([pallet,sscc]).reset_index(drop=True)
for i in range(len(pallet)):
df_sgtin = json_normalize(test[i]["down"]["childs"],["childs"])
df_sgtin["pallet"] = "Nan"
for f in range(len(df_sgtin)):
df_sgtin["pallet"][f] = pallet["sscc"][i]
pachka = pd.concat([pachka,df_sgtin]).reset_index(drop=True)
AG
VM
AG
VM
AG
I
VM