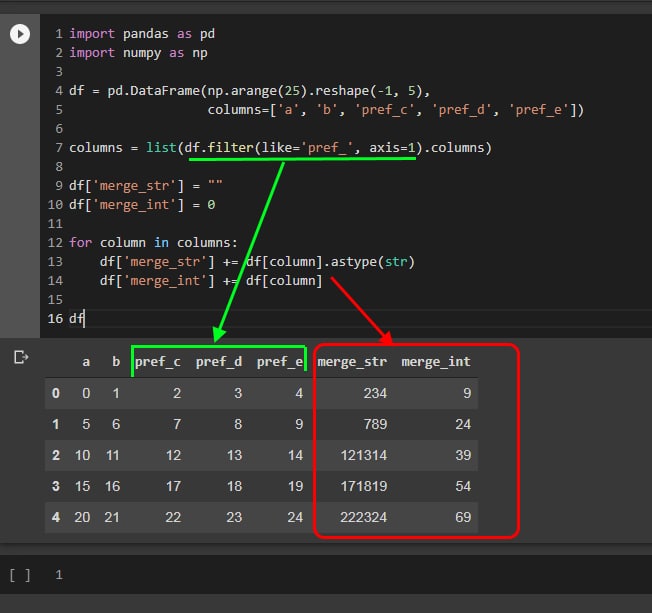
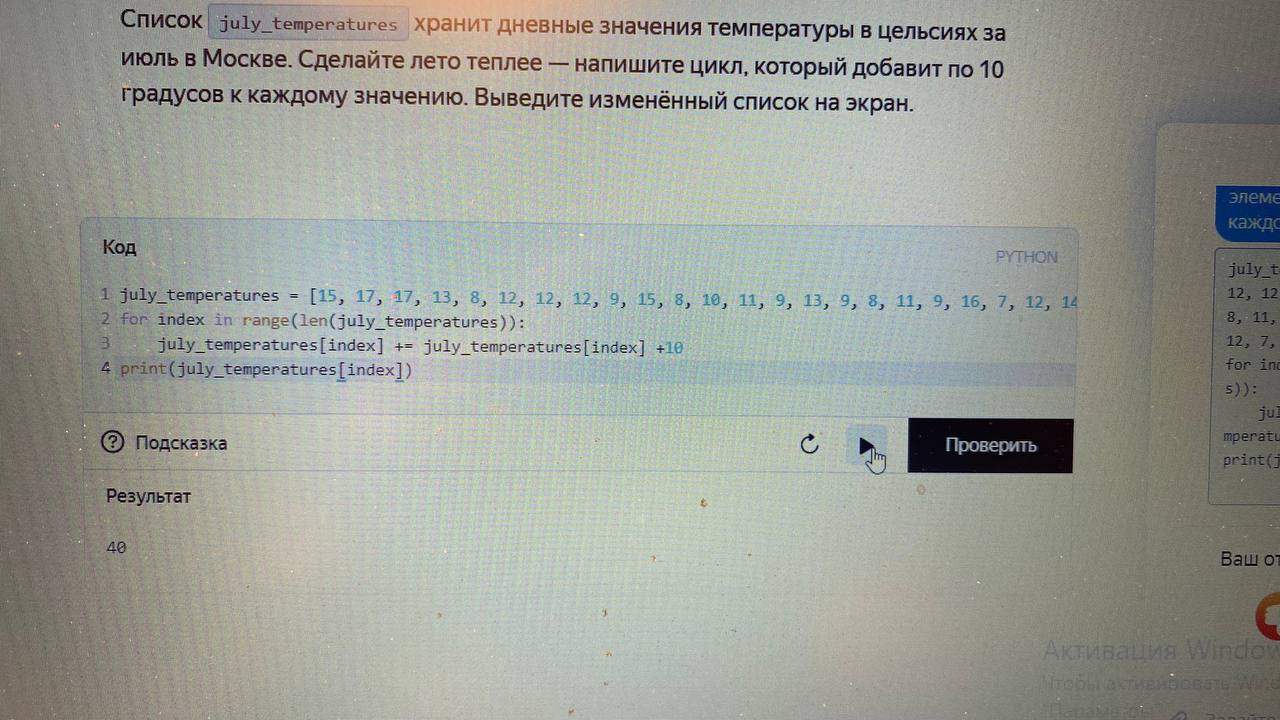
решающее дерево не подстраивается под ваши данные, если вы тренировали его на одних данных, оно не сможет сделать адекватные предсказания для данных лежащих в другом промежутке.
Решающее дерево создаёт оптимальные правила для деления данных на группы, минимизируя gini impurity в получившихся группах
Соответственно, если у вас существует правило для одних данных:
длина >1 => группа 2
Для других данных это правило не будет работать, так как у вас все значения будут попадать в одну группу (если данные в промежутке (500, 1000)), то есть это правило не приводит к делению на более однородные группы.
Если вам сильно нужно, то попробуйте стандартизировать величины, чтобы данные были сопоставимы.
но это все равно странно обучать модель на принципиально других данных