Sergey Sokolov
Добрый день, подскажите пожалуйста бест практис,
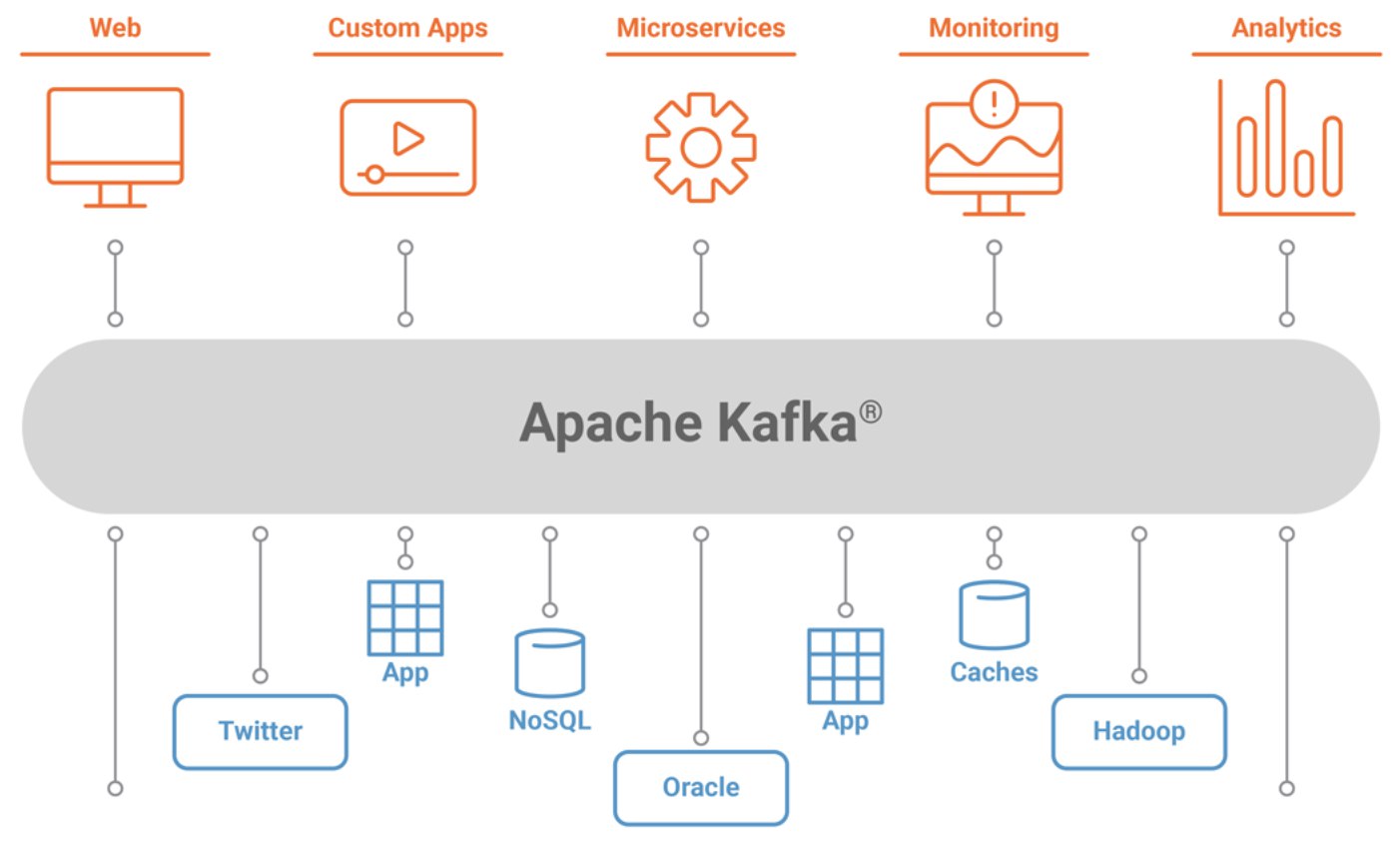
Задача в том чтобы реализовать взаимоедействие вебклиента с микросервисным бакендом, где микросервисы общаются между собой с помощью Kafka.
вопрос в первую очередь, как реализовать синхронное взаимодействие в виде request/reply ?
Думали сделать такой вариант: веб клиент генерит corellationId и выполняет запрос к бэку например createBook,
далее логика такая
1. бакнед подписывается на топик кафка book-created спомощью KafkaStreams делает filter по key=correlationId
2. бакнед отпарвляет команду CreateBookCmd в топик кафка book-create и среди прочего передает correlationId
3. далее какой-то консьюмер обрабатывает команду из топика book-create, создает Book и генерит BookCreatedEvent в топик book-created
4. бакенд получате событие из топика book-created с нужным corellationId и затем отдает ответ на вебклиента.
в таком сценарии получается что на каждый запрос вебклиента создается новый короткоживущий экземпляр KafkaStreams и вызывается start , stop
вопрос насколько ресурсоемко создание экземпляров KafkaStreams на каждый запрос от вебклиента?
как я понимаю такое решение аналогично созданию консьюмера для топика book-created с последующим чтением всех событий и отбрасыванию с несоотвсвующими corellationId.
Соответсвенно вопрос насколько ресурсоемко создание коньюмера на каждый запрос от вебклиента?
Может быть есть более правильные паттрены (что бы уйти от request/reply на фронте)?
Вряд ли бестпрактис уже сформировались. И много факторов есть, которые влияют на выбор решения. Добавлю свои 5 копеек.
1. Зачем столько разных топиков? Можно реквест-респонсы складывать в один, тогда сообщения с одинаковым ключом будут в одном партишне и упорядочены по времени. Консьюмеры будут фильтровать по ключу/хидерам и брать то, что нужно им, это достаточно дешево. В блоге конфлюент есть несколько постов на эту тему.
2. В чем профит создавать короткоживущий стрим? Выглядит как усложнение в описанном кейсе. Если все происходит в рамках одного реквест-респонса с фронта, то можно обойтись консьюмером из топика/партишна и хоть в памяти сервиса держать мапу с correlationId реквестов, так как шарить ее между несколькими инстансами смысла особого нет. Рядом можно список держать с отсортированными по времени реквестами, который пригодится для чистки мапы. Вариант плох тем, что поток должен будет простаивать и проверять мапу в ожидании ответа из топика, чтобы потом его отдать на фронт. Либо нужно менять схему реквест-респонс, и, например, процесс запускать с фронта на одном эндпоинте, а потом результат спрашивать на другом, опрашивая в цикле сервис, либо вебсокеты, как уже писали выше. Но тогда уже нужно шарить данные между инстансами и использовать бд или редис какой-нибудь.