VG
Size: a a a
2020 September 25
DL
Да
2020 September 26
VG
nice
2020 September 27
DS
Ребята, всем привет! Здесь можно посоветоваться касательно apche kafka?
DS
1. Есть некий топик для которого настроено больше одной партиции
2. Несколько инстансов приложения подписанных на данный топик (происходит параллельная обработка событий)
3. Сообщение публикуемое в топике имеет следующую структуру:
{
"group_id": 1,
// другие данные
}
Существует ли способ исключить параллельную обработку сообщений имеющих одно и тоже значение параметра "group_id" при наличии нескольких партиций и потребителей?
2. Несколько инстансов приложения подписанных на данный топик (происходит параллельная обработка событий)
3. Сообщение публикуемое в топике имеет следующую структуру:
{
"group_id": 1,
// другие данные
}
Существует ли способ исключить параллельную обработку сообщений имеющих одно и тоже значение параметра "group_id" при наличии нескольких партиций и потребителей?
DS
т.е. сделать последовательной для событий с одним group_id
SB
Dmitriy Smirnov
1. Есть некий топик для которого настроено больше одной партиции
2. Несколько инстансов приложения подписанных на данный топик (происходит параллельная обработка событий)
3. Сообщение публикуемое в топике имеет следующую структуру:
{
"group_id": 1,
// другие данные
}
Существует ли способ исключить параллельную обработку сообщений имеющих одно и тоже значение параметра "group_id" при наличии нескольких партиций и потребителей?
2. Несколько инстансов приложения подписанных на данный топик (происходит параллельная обработка событий)
3. Сообщение публикуемое в топике имеет следующую структуру:
{
"group_id": 1,
// другие данные
}
Существует ли способ исключить параллельную обработку сообщений имеющих одно и тоже значение параметра "group_id" при наличии нескольких партиций и потребителей?
Существует.
DS
Ключ рекорда Кафки да будет твоим group_id. Тогда один и тот же алгоритм хеширования будет отправлять все сообщения по той же самой группе в ту же самую партицию.
Да, придумал не самую удачную структуру данных, ну имеется в виду какой либо параметр (user_id к примеру). Я примерно понял концепцию, сейчас буду пробовать. А есть ли возможность вынести из программы данный функционал и перенести в кафку, к примеру в кафка стримс (честно говоря никогда этим не пользовался, по этому прошу прощения если этот вопрос звучит глупо)
SB
Dmitriy Smirnov
Да, придумал не самую удачную структуру данных, ну имеется в виду какой либо параметр (user_id к примеру). Я примерно понял концепцию, сейчас буду пробовать. А есть ли возможность вынести из программы данный функционал и перенести в кафку, к примеру в кафка стримс (честно говоря никогда этим не пользовался, по этому прошу прощения если этот вопрос звучит глупо)
Нет, партицировать по конкретному полю придётся программисту. Извини что так, передам ребятам что это неудобно. А Кафка Стримс с приставкой Стримс не просто так; верь или нет, но этот фреймворк обеспечивает потоковую обработку поверх Кафки и если у тебя нет реальной задачи, которая решается как обработка одного или многих взаимосвязанных или нет потоков (рекордов Кафки в разных топиках), то не нужно это тянуть как ещё одну зависимость.
DS
Нет, партицировать по конкретному полю придётся программисту. Извини что так, передам ребятам что это неудобно. А Кафка Стримс с приставкой Стримс не просто так; верь или нет, но этот фреймворк обеспечивает потоковую обработку поверх Кафки и если у тебя нет реальной задачи, которая решается как обработка одного или многих взаимосвязанных или нет потоков (рекордов Кафки в разных топиках), то не нужно это тянуть как ещё одну зависимость.
Оке, спасибо за помощь )
SB
А вот подумать тебе надо о следующем: стратегия рестарта (как восстановить состояние в пределах идентификатора? Можно ли полностью перечитать всю партицию для этого или там будет слишком много данных и это некстати)? Стратегия репартицирования? Что делать, когда ты захочешь удвоить количество партиций для горизонтально масштабирования? Будет промежуточное состояние, когда один и тот же идентификатор живет в разных партициях. Да и вообще про консистентность данных и SLA подумать, если они есть.
DS
А вот подумать тебе надо о следующем: стратегия рестарта (как восстановить состояние в пределах идентификатора? Можно ли полностью перечитать всю партицию для этого или там будет слишком много данных и это некстати)? Стратегия репартицирования? Что делать, когда ты захочешь удвоить количество партиций для горизонтально масштабирования? Будет промежуточное состояние, когда один и тот же идентификатор живет в разных партициях. Да и вообще про консистентность данных и SLA подумать, если они есть.
Я как раз об этом думал, о том что будет если придеться удвоить количество партиций и к чему это приведет. По этому спросил о возможном сущестовании такого механизма на стороне кафка, которая нивелирует возможные проблемы. Предпологаю что задача довольно распространена. Изначально думал написать свою реализацию на стороне приложения, которая по факту является прокси - очередью ))
SB
Такого механизма нет не только в Кафке, его нет даже в теории CS. Пока что максимум того что мы как индустрия в такой ситуации можем называется consistent hashing, призванный минимизировать объём съехавших данных. Но в целом твоё желание переложить ключевые решения, продиктованные конкретным запросом от бизнеса, на разработчиков Кафки - к добру не ведёт.
2020 September 28
VS
Такого механизма нет не только в Кафке, его нет даже в теории CS. Пока что максимум того что мы как индустрия в такой ситуации можем называется consistent hashing, призванный минимизировать объём съехавших данных. Но в целом твоё желание переложить ключевые решения, продиктованные конкретным запросом от бизнеса, на разработчиков Кафки - к добру не ведёт.
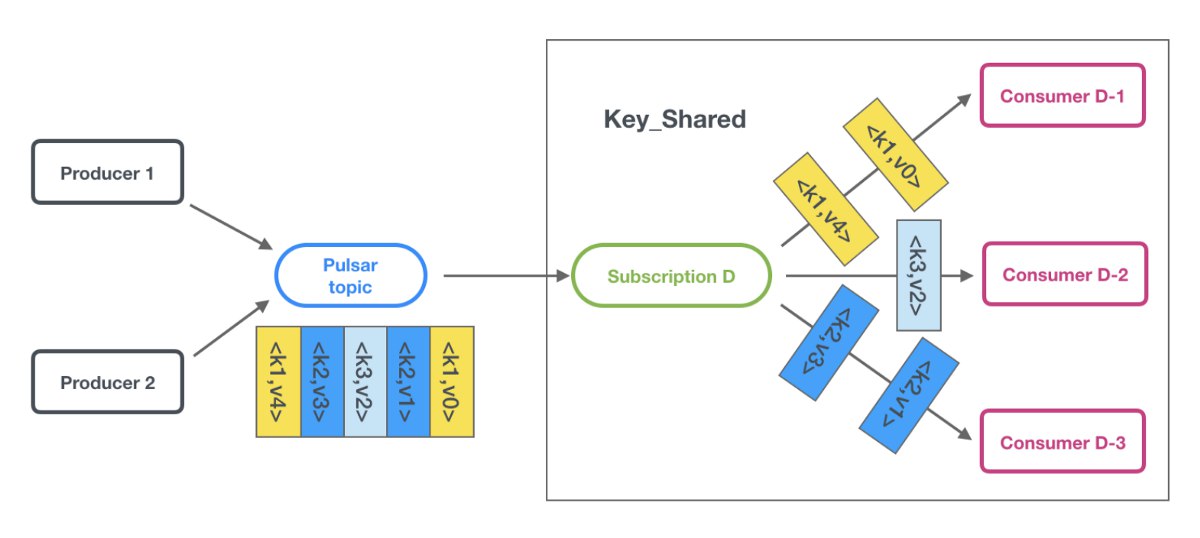
в пульсаре из коробки, называется key_shared https://medium.com/@ankushkhanna1988/apache-pulsar-key-shared-mode-sticky-consistent-hashing-a4ee7133930a