D
и никакого левенштейна не надо
Size: a a a
D
АБ
D
D
N
N
N
АБ
N
АК
АК
АК
VY
АК
VY
LM
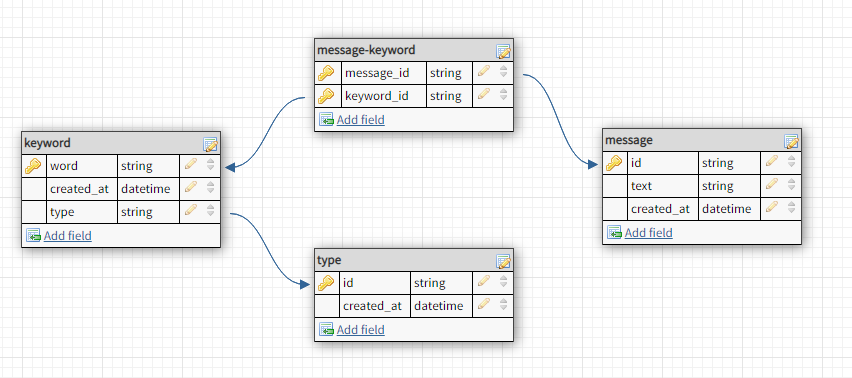
message заполняет один воркер, который отправляет пару keyword, message_id в другой воркер. И второй воркер должен создавать следующие записи в базе постгреса:type, если её нет.keyword, если её нет.message-keyword, если её нет.keyword в базе.on_conflict_do не используются, а используются savepoint перед каждым из шагов 1-3. Если возникла ошибка, то делаем rollback и идём дальше. Насколько это хорошо или плохо? Как это сделать более правильно? Единственное, что у меня на уме — это то, что необходимо сделать все эти добавления одной транзакцией, потому что в случае неудачи в воркере (хоть данные сейчас и записываются в самом конце работы воркера, но логика работы может измениться в скором времени) данные в базе должны быть в том виде, в котором они были до выполнения задачи.LM
D
message заполняет один воркер, который отправляет пару keyword, message_id в другой воркер. И второй воркер должен создавать следующие записи в базе постгреса:type, если её нет.keyword, если её нет.message-keyword, если её нет.keyword в базе.on_conflict_do не используются, а используются savepoint перед каждым из шагов 1-3. Если возникла ошибка, то делаем rollback и идём дальше. Насколько это хорошо или плохо? Как это сделать более правильно? Единственное, что у меня на уме — это то, что необходимо сделать все эти добавления одной транзакцией, потому что в случае неудачи в воркере (хоть данные сейчас и записываются в самом конце работы воркера, но логика работы может измениться в скором времени) данные в базе должны быть в том виде, в котором они были до выполнения задачи.LM
D