Всем привет)
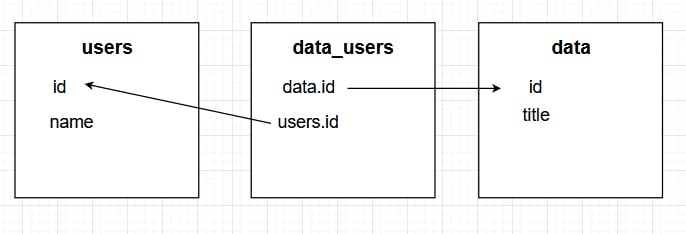
Есть таблица users и data
Предполагается, что у каждого юзера может быть несколько строчек из data
В таком случае же делается отдельная таблица для связки users => data?
Какой тогда primary key будет? Он же должен быть уникальным.
А тут один юзер будет иметь несколько строк с
data.idИли сделать наоборот
Primary key ==
data.id?
Какая практика вообще в таких случая приветствуется?
Cпасибо)