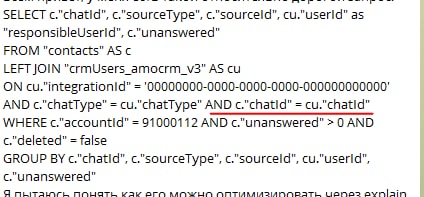
Всем привет, у меня есть такой относительно дорогой запрос:
SELECT c."chatId", c."sourceType", c."sourceId", cu."userId" as "responsibleUserId", c."unanswered"
FROM "contacts" AS c
LEFT JOIN "crmUsers_amocrm_v3" AS cu
ON cu."integrationId" = '00000000-0000-0000-0000-000000000000' AND c."chatType" = cu."chatType" AND c."chatId" = cu."chatId"
WHERE c."accountId" = 91000112 AND c."unanswered" > 0 AND c."deleted" = false
GROUP BY c."chatId", c."sourceType", c."sourceId", cu."userId", c."unanswered"
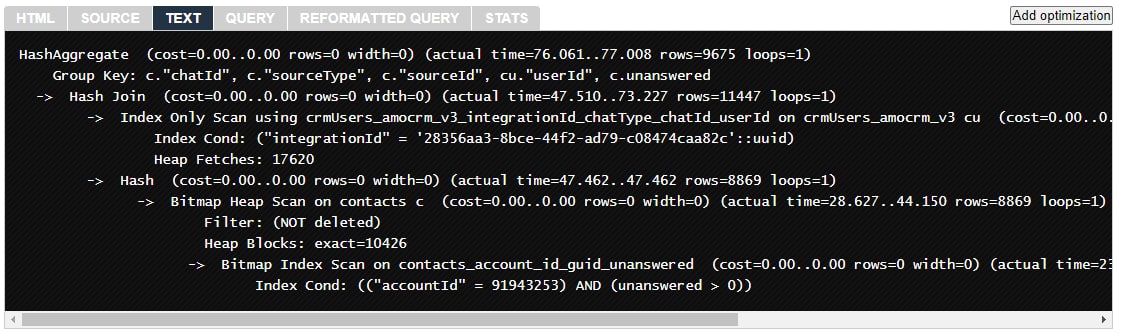
Я пытаюсь понять как его можно оптимизировать через explain analyse, получаю вот такой план -
https://explain.depesz.com/s/hclB.
Если честно не сильно разбираюсь в индексах и как их правильно применять, но планирую добавить вот такой индекс - CREATE INDEX contacts_account_id ON contacts (accountId) WHERE unanswered > 0 AND deleted = false, это ускорит выполнение моего запроса?