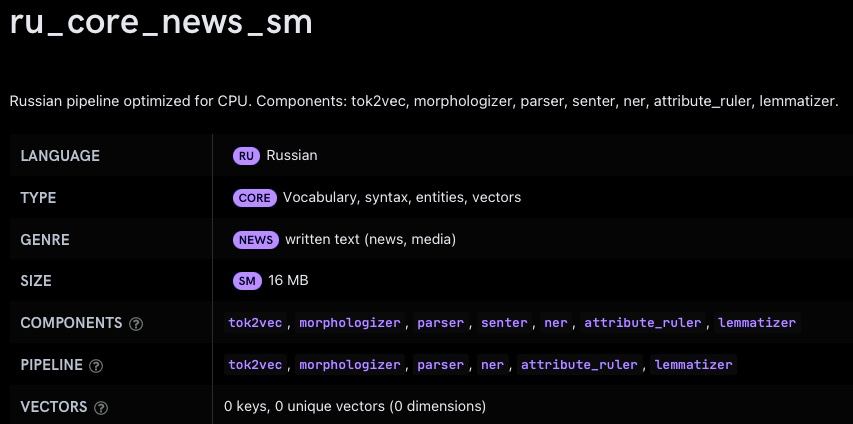
Встречаем русские модели в официальном каталоге Spacy !
Мы плыли, плыли, и наконец приплыли:
https://nightly.spacy.io/models/ru( вошло в
https://github.com/explosion/spaCy/releases/tag/v3.0.0rc3 )
Модели там только для spacy 3.0 , а для версии 2.3 модели у меня:
https://github.com/buriy/spacy-ruогромное спасибо Саше
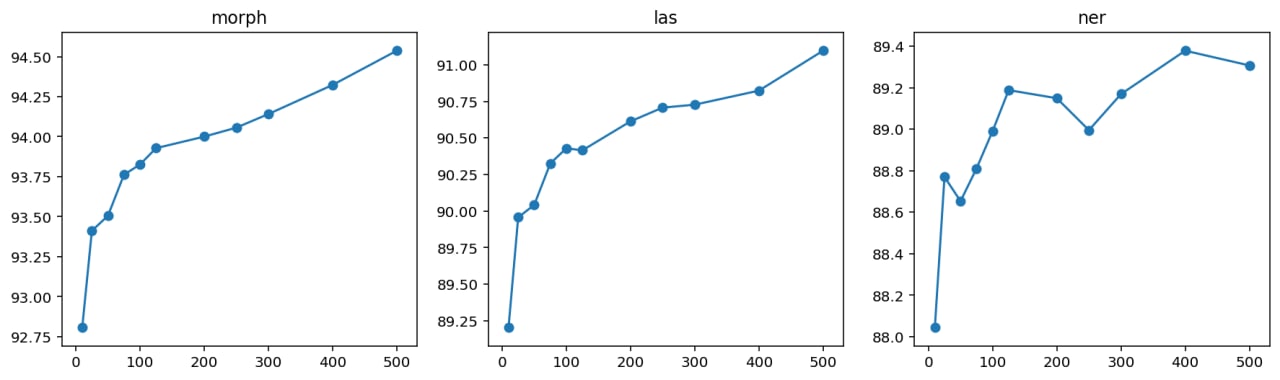
@alexkuk за подготовку релиза и датасетов и немного спасибо мне. И конечно спасибо контрибуторам в spacy-ru , что помогли нам проложить дорогу к светлому будущему. Ещё не всё вошло в этот релиз, только самое основное. Будем улучшать в частности лемматизацию и выделение noun_chunks, а потом и токенизацию. И релиз с трансформерами сделаем.