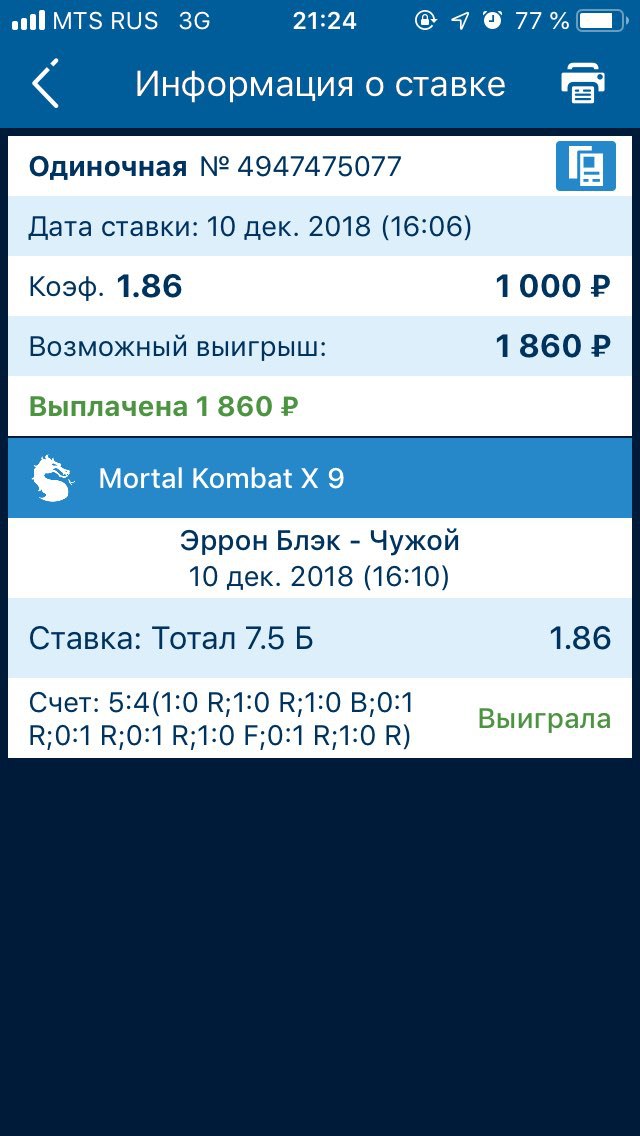
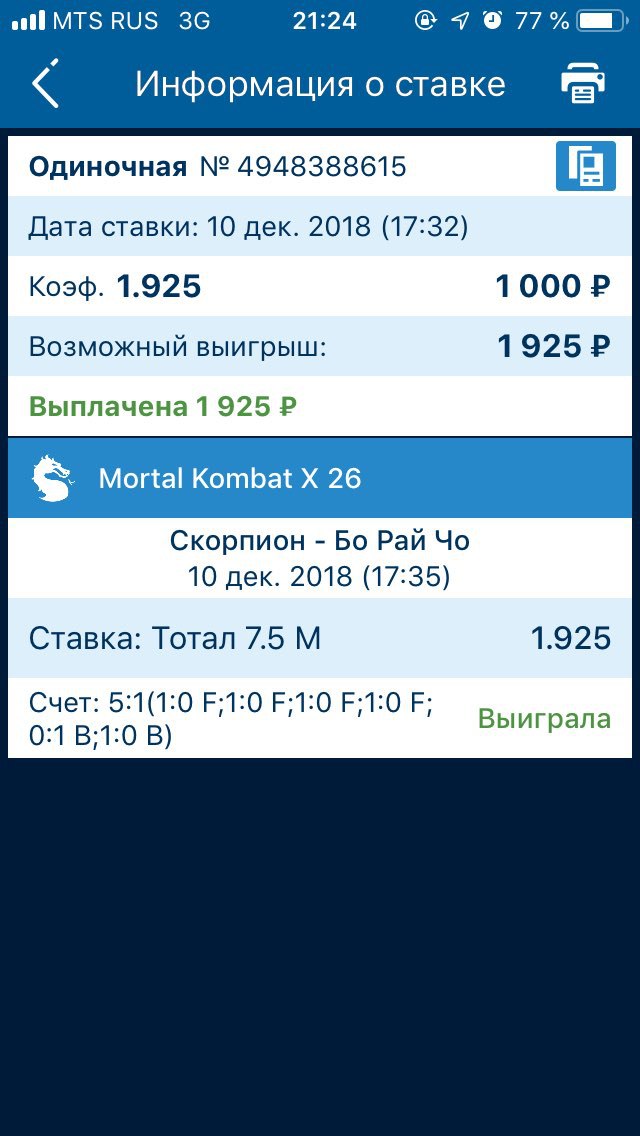
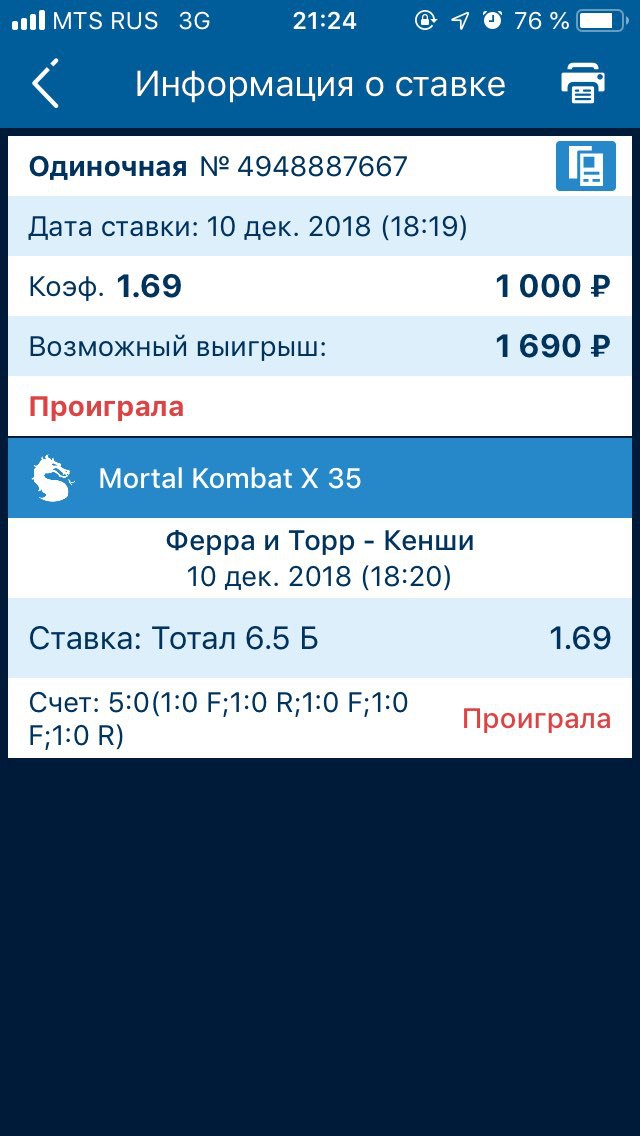
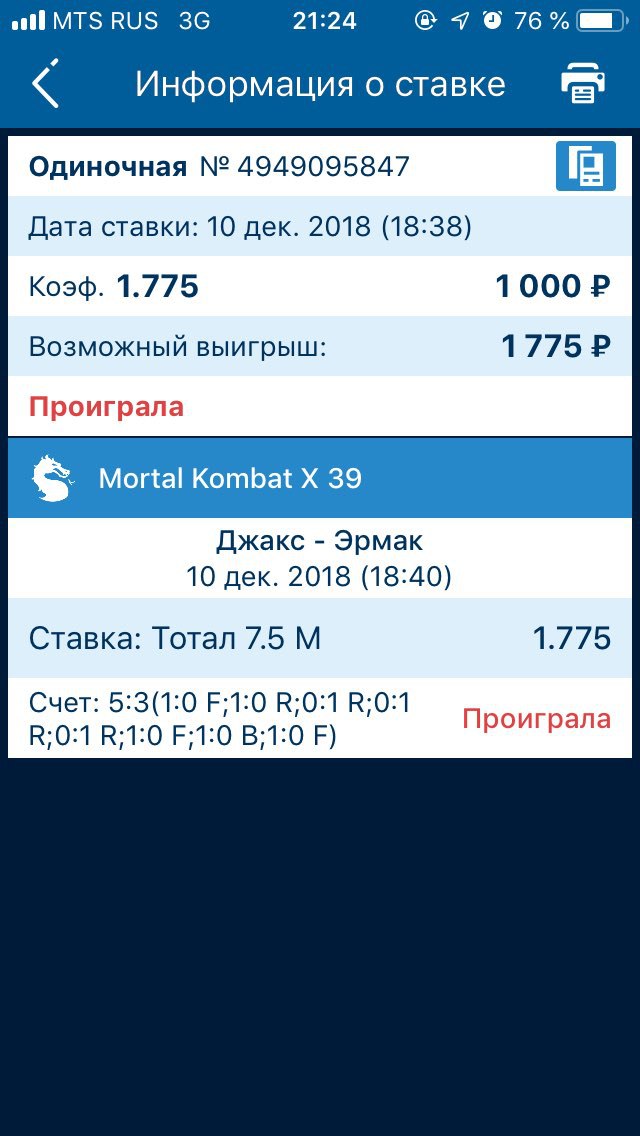
AlphaZero самостоятельно учится играть в игры на высочайшем уровне 🕹
Группа ученых из группы DeepMind и Университетского колледжа в Лондоне разработала систему искусственного интеллекта, способную самообучаться игре и совершенствованию в трех сложных настольных играх. В своей работе, опубликованной в журнале Science, ученые описывают свою новую систему и объясняют, почему считают, что она представляет собой большой шаг в направлении развития будущих систем ИИ.
Новая система под названием AlphaZero представляет собой систему обучения с подкреплением, то есть обучается, многократно играя в игру и учась на своем опыте. Это, разумеется, очень похоже на процесс обучения людей. Задается базовый набор правил и компьютер играет в игру — сам с собой. Ему даже партнеры не нужны. Он играет сам с собой много раз, отмечая хорошие и победные ходы. Со временем он становится все лучше и лучше, превосходит не только людей, но и другие системы ИИ, разработанные для настольных игр. Данная система также использовала метод поиска «древа поиска Монте-Карло». Совмещение двух технологий позволило системе научиться совершенствованию в игре. Ученые опробовали силы программы, обеспечив ее большой мощностью — 5000 тензорных процессоров, работающих в паре с большим суперкомпьютером.