AZ
Странно, что почти нигде нет такой штуки как LIMIT n,m BY key1, key2 тк она кажется достаточно естественной
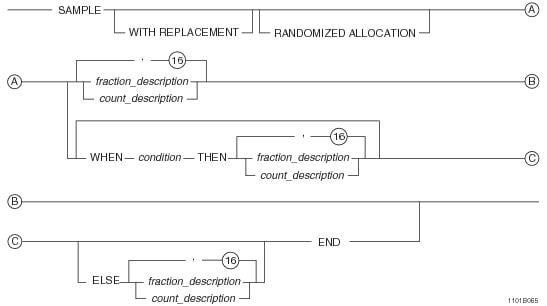
у нас есть SAMPLE который может вообще что угодно
SELECT city, state, SAMPLEID
FROM stores
SAMPLE WHEN state = 'WI' THEN 0.25
WHEN state = 'CA' THEN 0.5
END
ORDER BY 3;
SELECT city, state, SAMPLEID
FROM stores
SAMPLE WHEN state = 'WI' THEN 0.25
WHEN state = 'CA' THEN 0.5
END
ORDER BY 3;