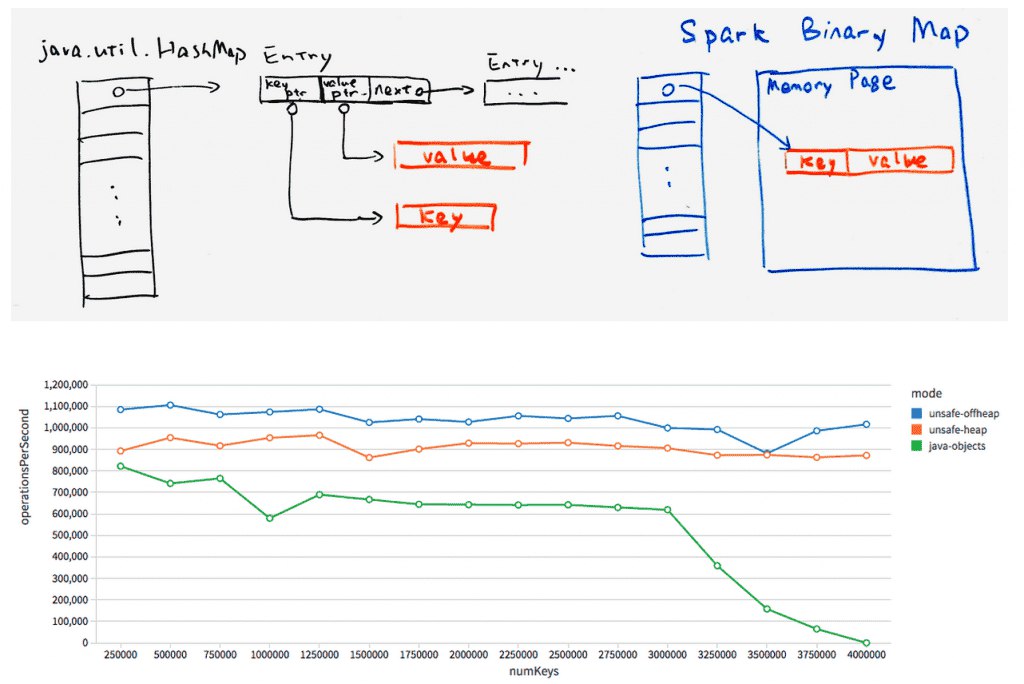
Как раз недавно смотрел, интересовался. Ballista основана на Data Fusion, это проект Энди Гроува, движок обработки запросов, теперь часть Apache Arrow, и это, конечно хорошо. Что не очень хорошо, так то что тулза в разработке. The main focus now is getting the platform to a level of maturity where users can run real-world ETL workloads (с). Энди Гроув пытается больше задействовать сообщество для развития, но к промышленному применению тулза не готова. Не вижу поддержки джоинов, агрегатных фукнций очень мало, файловых форматов только два (csv и parquet). На будущее (несколько лет) может быть хороший вариант, сейчас можно присоединяться к сообществу, развивать проект, ресерчить
Конечно, с самого начала ориентирована на kubernetes, а не на yarn
От сериализации, по-моему, полностью не избавиться, но arrow всегда заявляют минимальный оверхед
Спасибо за развернутый ответ!