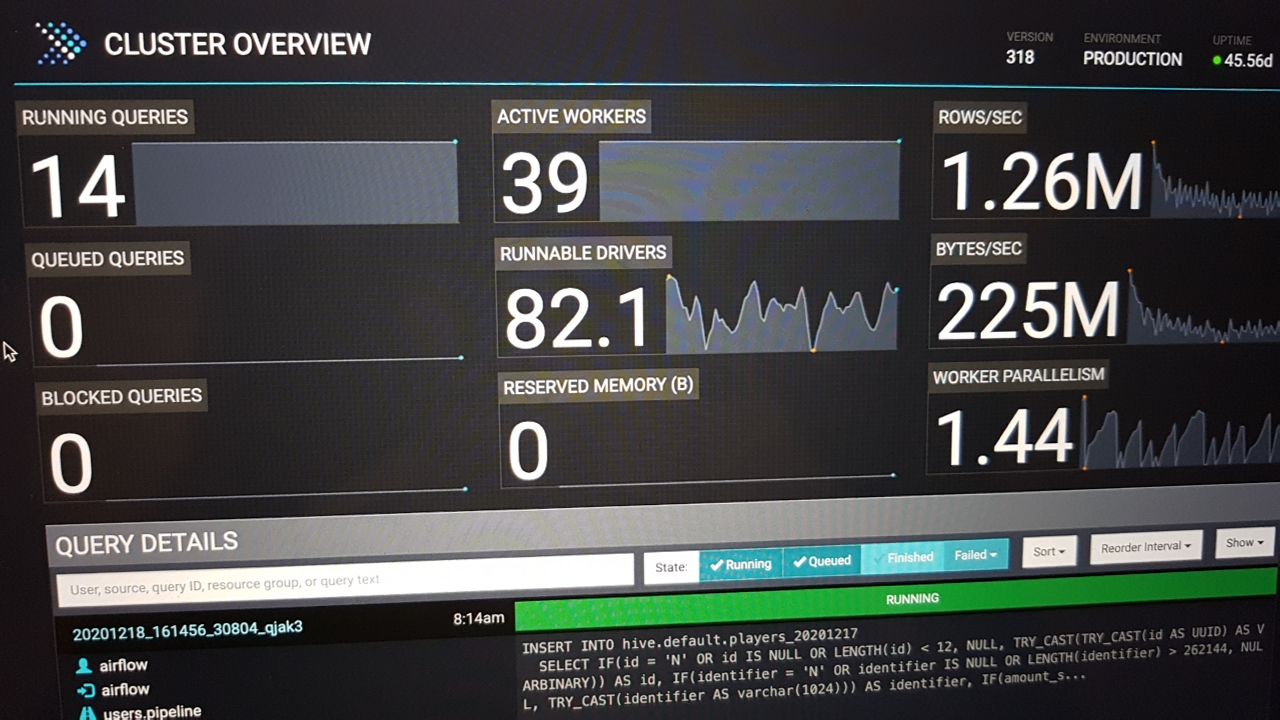
Кмк вам надо посмотреть на то куда время в этих запросов уходит, я готов поставить кружку пилзнера что вы подпираете IO, на кластере из 4 узлов при RF3 у вас каждый диск с которого читают с высокой вероятностью и в записи участвует (у вас там insert select виден); мб вы переросли кластер и пора расширяться
Спасибо большое, так и есть - предыдущий владелец весь ETL сделал через presto SQL и поэтому нагрузка на hdfs двойная, с одной стороны запросы на инсерты и с другой аналитика. Я с presto встретился 3 недели назад, поэтому прошу прощения за тупые вопросы.