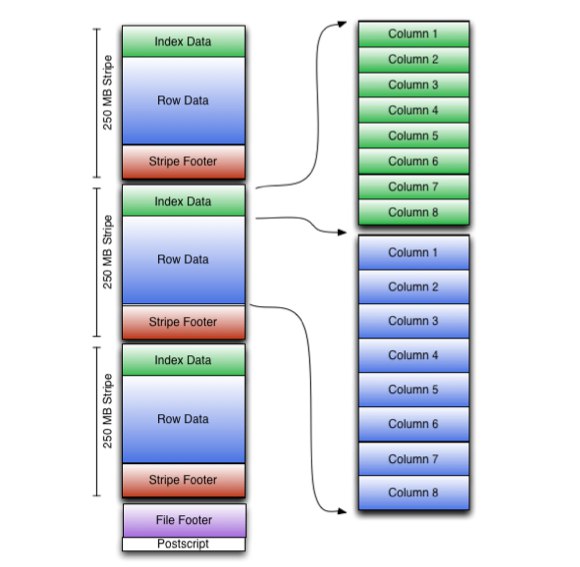
Кстати если кому-то надо сделать публикацию (или ведет студентов которым надо), отличная тема - обзор работы PDO по Parquet/ORC для разных компьют фреймворков - и в журнал возьмут, и на конференцию.. У меня был студент который было начал, но отвалился в середине семестра :(
Публикации часто ограничиваются тем, что показывают планчик spark, в котором видно pushed-down predicate ‘x’=42, спасибо, так и мы можем)) Хорошо бы сделать действительно жирную статью, где и плюсы и минусы, и как вообще к этому подойти. Но я вот работаю только с parquet, а тут я видел ссылку на интересный материал по ORC, но паркет там не упоминался. Если делать коллективно, значит надо договариваться, обмениваться опытом, работать в общем ^^