N
Привет 👋
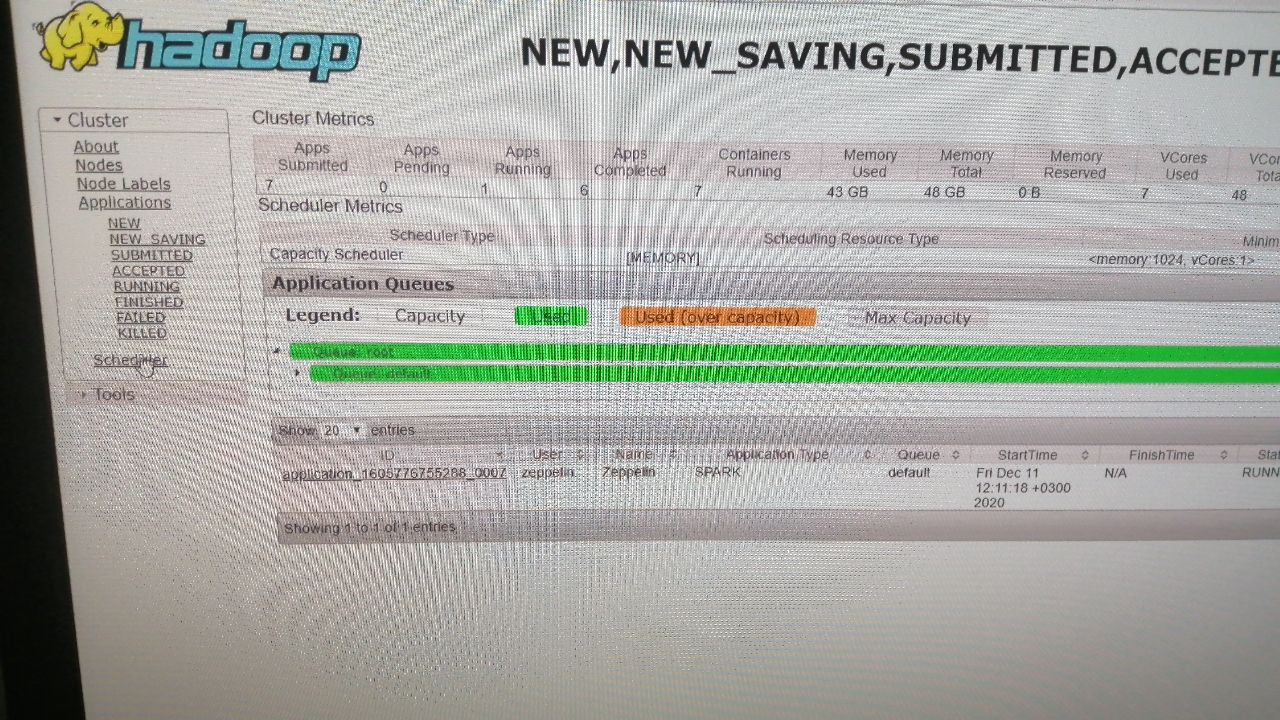
Zeppelin использует ресурс hadoop (ядра и hdfs) , поставили задачу оптимизировать процессы запроса Zeppelin через Spark к логам на hdfs. Просто на мощный запрос все ядра уходят, а остальные в очереди запросы толпятся курят. Посоветуйте литературу оптимизации yarn!? Что бы не все ядра уходили на такой запрос..
Zeppelin использует ресурс hadoop (ядра и hdfs) , поставили задачу оптимизировать процессы запроса Zeppelin через Spark к логам на hdfs. Просто на мощный запрос все ядра уходят, а остальные в очереди запросы толпятся курят. Посоветуйте литературу оптимизации yarn!? Что бы не все ядра уходили на такой запрос..
гугли yarn scheduler (fair, capacity)