мне нужен был прям нормальный SQL to map collection с предикатами, и я его уже для себя написал. с ANTLR парсером и RPN стеком, как по учебнику. два дня работы.
Всем привет. Кто-нибудь пользовался distributed kmodes (kmean clustering) на скале или джаве? Пользовался ли спарковскими библиотеками или какой то другой?
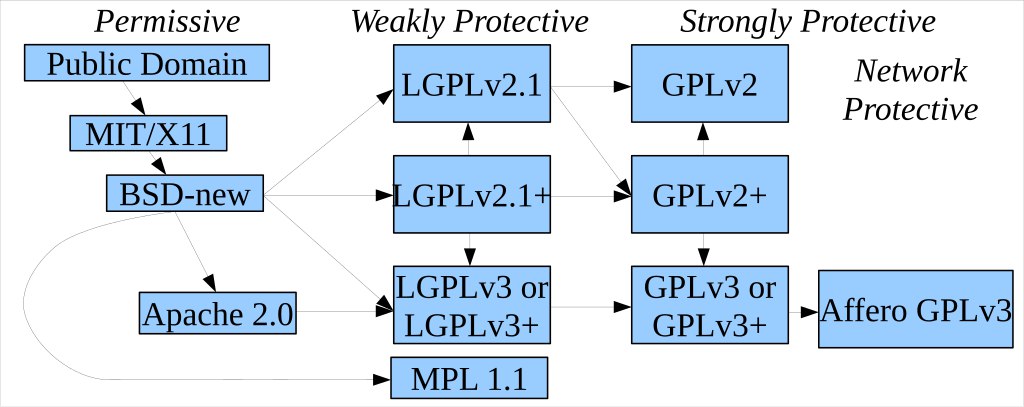
Вопрос! есть опенсорсный софт с лицензией если его форкнуть и переписать немножк то можно ли будет потом покрыть его другой лицензией? и можно ли будет старую выкинуть или придется оставить что-то вроде Multi-licensing?
Вопрос! есть опенсорсный софт с лицензией если его форкнуть и переписать немножк то можно ли будет потом покрыть его другой лицензией? и можно ли будет старую выкинуть или придется оставить что-то вроде Multi-licensing?