кстати если кому надо строить PMML pipeline то теперь по крайней мере для скоринга есть PMML4S с лицензией Apache, если вы пишете коммерческий софт с закрытым кодом - то можно не платить Виллу)
PMML file создал. Вроде по данным в нем pipeline смог заменить missing values на те, что прописаны в аргументе (заменяю на самое частое встречающееся значение). Мои версии:
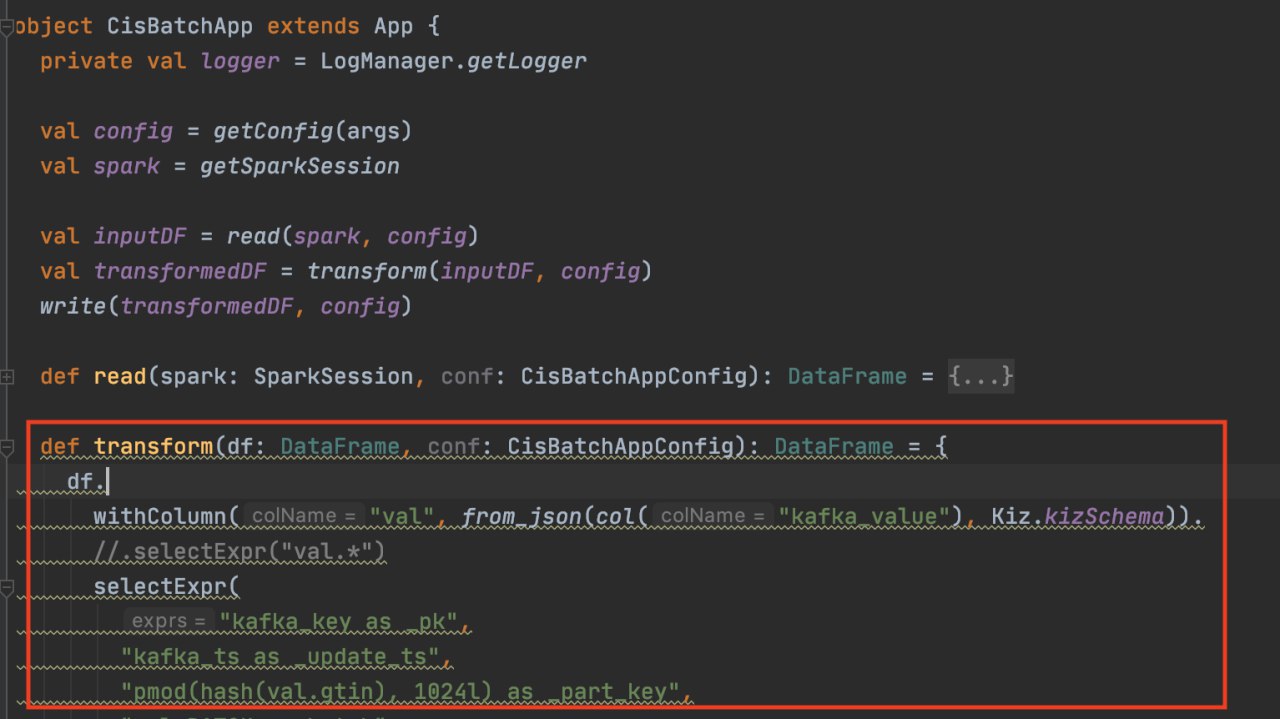
мне либо проверять все возможные комбинации в исходном датафрейме (и жисоне внутри него), либо делать цепочку трансформаций через Spark DSL: withColumn("newCol1", my_transform_func1(col("oldCol1"))). withColumn("newCol2", my_transform_func2(col("oldCol2"))).
Всем привет, подскажите пожалуйста, какие бест пректизы с использованием спарка и эйрфлоу. Нужно ручками собирать джарник и подсовывать или есть какие-то более изящные решения?
Всем привет, подскажите пожалуйста, какие бест пректизы с использованием спарка и эйрфлоу. Нужно ручками собирать джарник и подсовывать или есть какие-то более изящные решения?
оО... тоже интересует правильный ответ на этот вопрос!