A
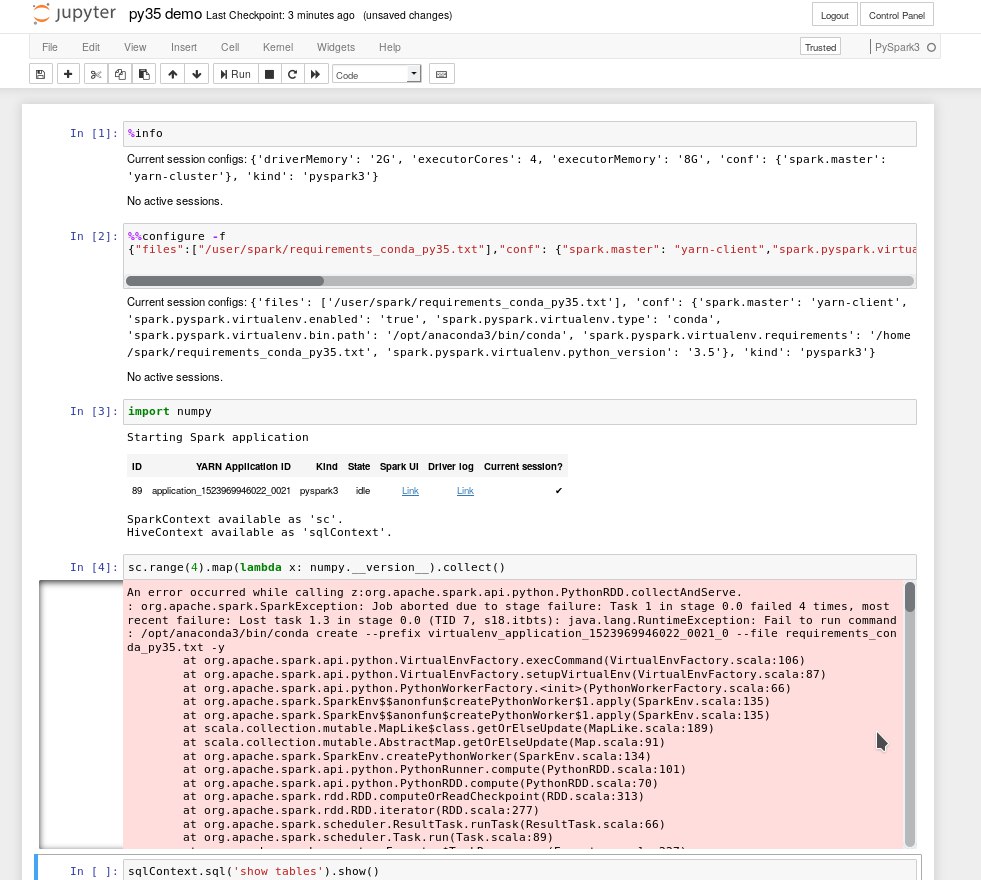
@igor_dia сейчас в процессе портирования патча из хортоновского спарка чтобы поддерживать sc_install_packages
https://community.cloudera.com/t5/Community-Articles/Using-VirtualEnv-with-PySpark/ta-p/245932
https://community.cloudera.com/t5/Community-Articles/Using-VirtualEnv-with-PySpark/ta-p/245932