IMPORTDATA: импорт данных из CSV-файлов
Раз уж мы упомянули о функции IMPORTDATA в предыдущем посте, расскажем вкратце и о ней.
Она позволяет загружать в Google Таблицу данные из файлов формата csv (comma separated values; данные, разделенные запятыми).
И единственный ее аргумент - ссылка на файл.
Как и в остальных функциях, можно ссылку разместить в ячейке, а из самой функции сослаться на ячейку.
Или же можно ссылку в кавычках указать внутри скобок функции в качестве единственного аргумента.
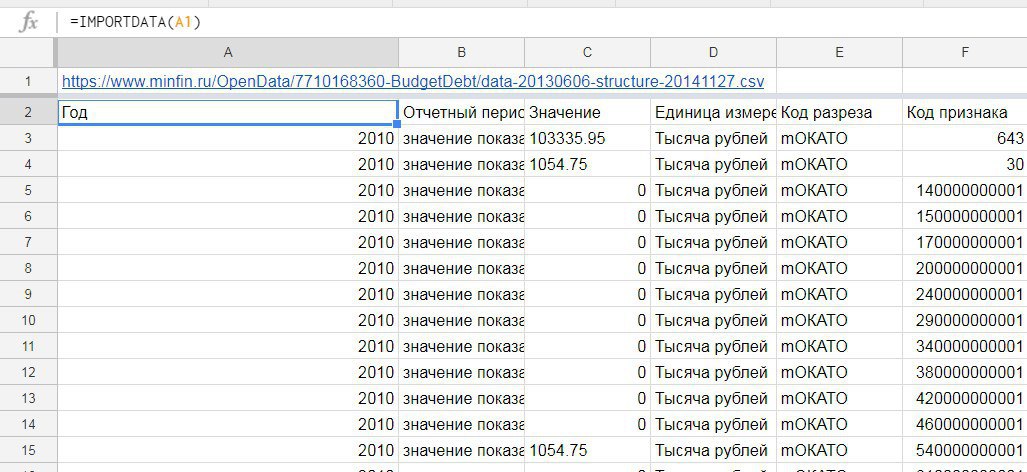
Для примера возьмем ссылку на один из открытых источников данных на сайте Минфина - например, о задолженности по исполнению обязательств перед гражданами (скриншот 1)
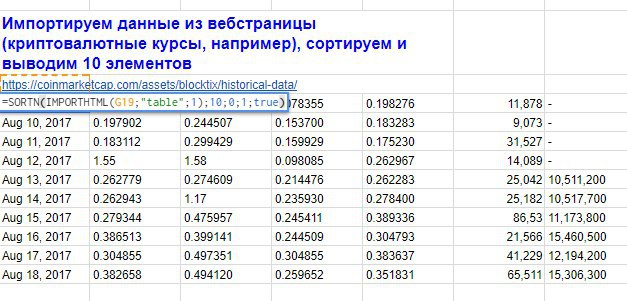
Вставим в ячейку в Google Таблице и сошлемся на эту ячейку функцией IMPORTDATA (скриншот 2).
Всем хорошей недели!
Раз уж мы упомянули о функции IMPORTDATA в предыдущем посте, расскажем вкратце и о ней.
Она позволяет загружать в Google Таблицу данные из файлов формата csv (comma separated values; данные, разделенные запятыми).
И единственный ее аргумент - ссылка на файл.
Как и в остальных функциях, можно ссылку разместить в ячейке, а из самой функции сослаться на ячейку.
Или же можно ссылку в кавычках указать внутри скобок функции в качестве единственного аргумента.
Для примера возьмем ссылку на один из открытых источников данных на сайте Минфина - например, о задолженности по исполнению обязательств перед гражданами (скриншот 1)
Вставим в ячейку в Google Таблице и сошлемся на эту ячейку функцией IMPORTDATA (скриншот 2).
Всем хорошей недели!