KP
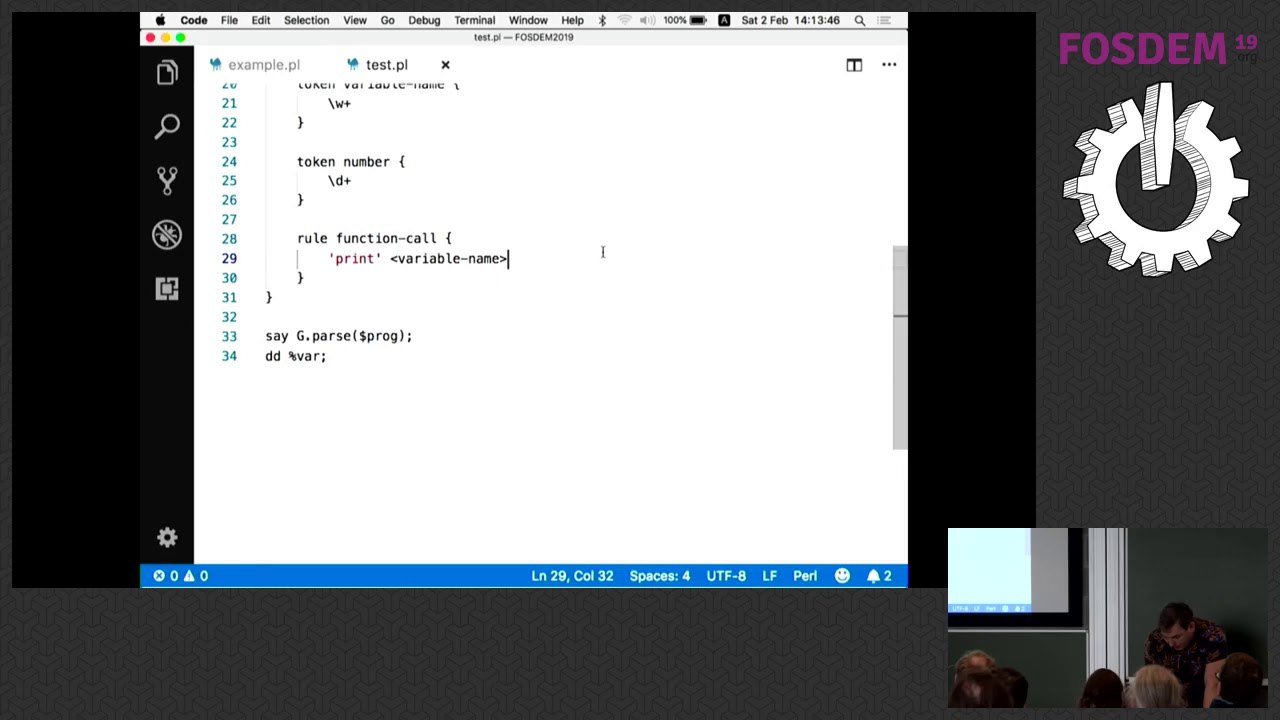
Потом ты с этим AST дрочишь вприсядку, и генерируешь из него либо прямо машинные коды (но так никто не делает, ибо сложна и не портабельно), либо какой-то промежуточный язык (IR) для чего-то, что этот IR сможет либо скомпилировать в нужные ассемблеры (как правило там есть ещё линковка и оптимизация на всех этапах, задарма; самый типовый пример — LLVM, который как раз довольно вменяемый фреймфорк для кодогенерации, если ты не норкомант из проекта ТОН и не хочешь 257-битные байты); или твой IR это уже "мета-ассемблер", набор опкодов для виртуальной машины-интерпретатора