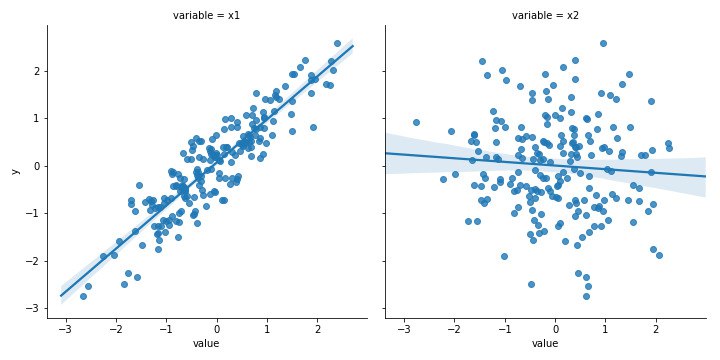
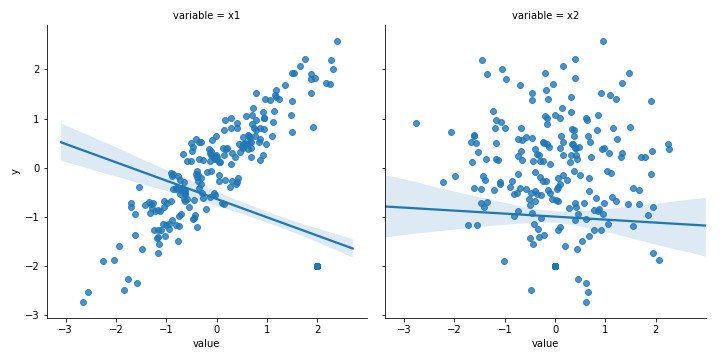
Неполное понимание целевой функции
Аналитики хотят создать «лучшую» модель. Но красота в глазах видящего. Если вы не знаете, в чем заключается основная задача и целевая функция, не знаете, как модель себя ведёт, то вряд ли построите «лучшую» модель. Кроме того, задача может заключаться в улучшении бизнес-метрики, а не в построении математической функции.
Решение: У большинства победителей Kaggle уходит много времени на понимание целевой функции и того, как с ней связаны модель и данные. Необходимо оптимизировать бизнес-метрику, сопоставьте её с соответствующей целевой функцией.
Пример: для оценки моделей классификации используется F-мера. Однажды была построена модель классификации, успех которой зависел от того, в каком проценте случаев она была правильной. Как выяснилось, F-мера вводит в заблуждение, потому что показывает, что модель была правильной примерно 60% времени, а на самом деле — только 40%.
Аналитики хотят создать «лучшую» модель. Но красота в глазах видящего. Если вы не знаете, в чем заключается основная задача и целевая функция, не знаете, как модель себя ведёт, то вряд ли построите «лучшую» модель. Кроме того, задача может заключаться в улучшении бизнес-метрики, а не в построении математической функции.
Решение: У большинства победителей Kaggle уходит много времени на понимание целевой функции и того, как с ней связаны модель и данные. Необходимо оптимизировать бизнес-метрику, сопоставьте её с соответствующей целевой функцией.
Пример: для оценки моделей классификации используется F-мера. Однажды была построена модель классификации, успех которой зависел от того, в каком проценте случаев она была правильной. Как выяснилось, F-мера вводит в заблуждение, потому что показывает, что модель была правильной примерно 60% времени, а на самом деле — только 40%.