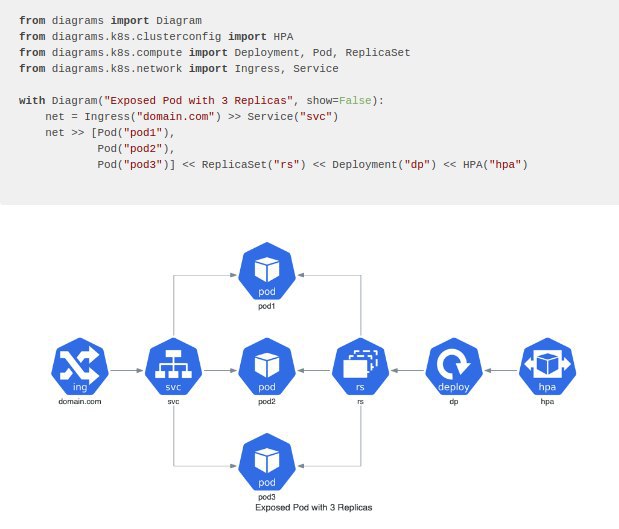
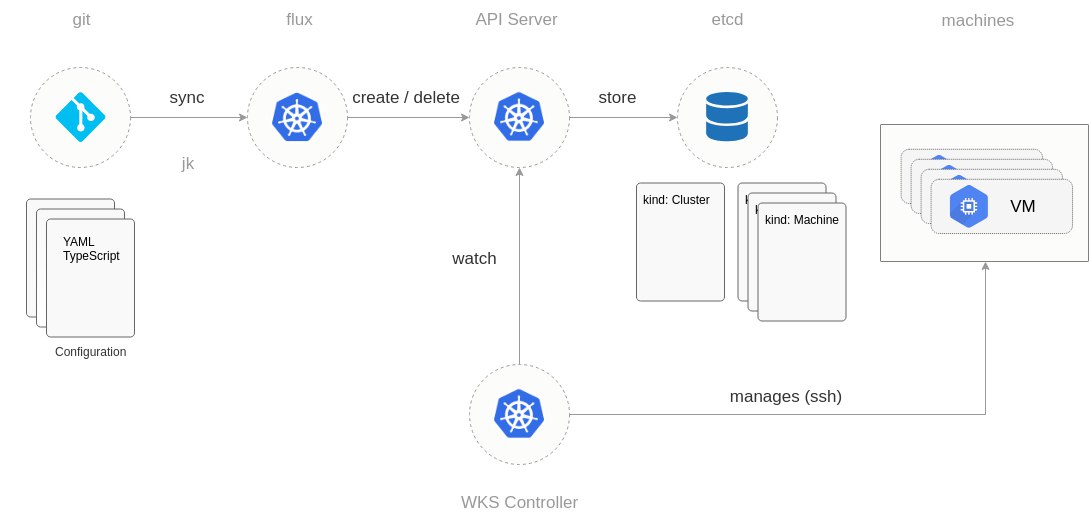
Если вы помните, пару недель назад я публиковал пост, где написал, что мне предоставили возможность сходить на курсе Slurm по SRE. Так вот, я сходил и хотел бы поблагодарить организаторов за гостеприимство и рассказать о своих впечатлениях. В первый раз, когда я услышал про этот курс, мое отношение было очень скептическим - как можно за три дня, сделать из человека SRE? Позже, я подумал что в целом, опытному опсу или разработчику вполне можно за это время рассказать основные принципы - в конечном итоге, SRE book вполне читается за день-два и тогда я решил что ребята просто перескажут книжку за определенную сумму денег, что вполне себе тоже вариант для занятых людей, в дальнейшем, когда я пообщался с организаторами, я понял что они основной упор собираются давать на практику и мне стало интересно. Собственно, на курс я ехал с небольшим скепсисом (сам то я SRE book прочел достаточно давно), но забегая вперед скажу что получилось достаточно неплохо, особенно учитывая что я был на первом потоке, а про первый блин мы с вами прекрасно знаем. Теперь о курсе: во-первых, slurm взяли работающих инженеров из Booking и даже Google, что я считаю, действительно круто и избавило их от претензий касательно компетентности преподавателей, во-вторых: организация курса вполне удачная - всех участников разбили по командам из пяти человек, стараясь чтобы в одну команду не попали коллеги из одной компании, у каждой команды был ментор и отдельный чат с поддержкой для решения тех проблем, которые не то чтобы были критичны, но возникали. Теперь, что касательно, содержательной части - всех участников, делят на команды, читают теоретическую часть, которой обычно немного, и дают задание - некий "инцидент", команды должны разобраться и починить, получая баллы за решения. Сами задания выбраны вполне удачно и на мой взгляд приближенный к тому что делают SRE - не буду раскрывать подробности, но некоторые из них вполне заставили попотеть. Работать приходится с вполне "модным" сейчас стеком - Kubernetes\Prometheus\Gitlab\Grafana с проектом, который выглядит "как живой" и даже имеют документацию. Заданий очень много, времени впритык да и организаторы вводят дополнительные игровые элементы стресса, так что скучать не придется. Темп курса вполне себе интенсивный - к третьему дню я понял, что даже успел подустать. Что понравилось - вполне релевантные задачи и достаточно реалистичные условия, теория без "отсебятины" и повторяет то что есть в книге, да и вообще в общем доступе. Не было ощущения "снежного кома", когда у тебя не выходило справиться с заданиями - давались подсказки, затем, по истечению времени, давались решения и дополнительное время на то чтобы их выкатить. Очень весело работать именно командой - мне с ребятами вполне повезло, мы легко нашли общий язык и работали вполне слаженно, хоть и не сразу. Что не понравилось: все таки темп великоват, как мне кажется, но это конечно субъективно. Так же были шероховатости касательно заданий и времени на них отведенных, подсчета баллов, но это явно проблемы первого потока и в дальнейшем это решат, я уверен. Подведу итог: если вы, как я писал выше, опытный системный администратор, который не боится кодить, бекендер, который хочет расширить свой scope или devops (AKA человек-методология) - приходите, вам точно понравится. Если вы не знаете технологий, которые используются в стеке курса или никогда не программировали, вам будет сложно. Точно не стоит на курс идти тем, кто в индустрии совсем недавно, курс совсем не для новичков - скорее всего вы будете балластом в команде и кроме сумбурной мешанины в голове у вас ничего не останется. Не подойдет он уже и тем кто сейчас уже работает SRE - курс рассчитан на ознакомление с практиками и есть риск что все происходящее вам очень напомнит работу ;) В целом впечатления остались положительные, пообщался с тиммейтами, среди них есть ребята из регионов - они тоже довольны и считают курс более чем полезным, собираются теперь нести SRE на местах #sre #slurm