



RN
cnuernber/libpython-clj: libpython bindings into the techascent ecosystem
https://github.com/cnuernber/libpython-clj
https://github.com/cnuernber/libpython-clj
Size: a a a
RN
ST
T
ST
A
ST
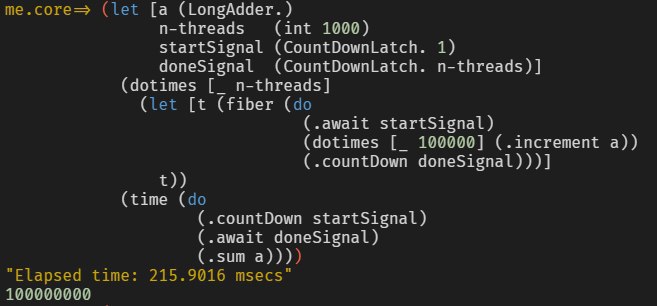
(criterium/quick-bench
(loop [i (int 0)
n (int 1e8)]
(if (pos? n)
(recur (unchecked-inc i) (unchecked-dec n))
i)))
Evaluation count : 12 in 6 samples of 2 calls.
Execution time mean : 59,346057 ms
Execution time std-deviation : 365,605235 µs
Execution time lower quantile : 58,905549 ms ( 2,5%)
Execution time upper quantile : 59,869274 ms (97,5%)
Overhead used : 1,808581 ns
=> nil
(criterium/quick-bench
(let [limit (int 1e8)
parallelism 100
chunk-size (int (/ limit parallelism))
from (async/to-chan (vec (repeat parallelism 1)))
to (async/chan parallelism)
work (async/pipeline parallelism
to
(map (fn [_]
(loop [i (int 0)
n (int chunk-size)]
(if (pos? n)
(recur (unchecked-inc i) (unchecked-dec n))
i))))
from
true)]
(do
(async/<!! work)
(async/<!!
(async/reduce + 0 to)))))
Evaluation count : 42 in 6 samples of 7 calls.
Execution time mean : 15,824584 ms
Execution time std-deviation : 189,562450 µs
Execution time lower quantile : 15,691798 ms ( 2,5%)
Execution time upper quantile : 16,145688 ms (97,5%)
Overhead used : 1,808581 ns
Found 1 outliers in 6 samples (16,6667 %)
low-severe 1 (16,6667 %)
Variance from outliers : 13,8889 % Variance is moderately inflated by outliers
=> nil
ST
ST
ST
ST
ST
(criterium/quick-bench
(loop [i (int 0)
n (int 1e8)]
(if (pos? n)
(recur (unchecked-inc i) (unchecked-dec n))
i)))
Evaluation count : 12 in 6 samples of 2 calls.
Execution time mean : 59,346057 ms
Execution time std-deviation : 365,605235 µs
Execution time lower quantile : 58,905549 ms ( 2,5%)
Execution time upper quantile : 59,869274 ms (97,5%)
Overhead used : 1,808581 ns
=> nil
(criterium/quick-bench
(let [limit (int 1e8)
parallelism 100
chunk-size (int (/ limit parallelism))
from (async/to-chan (vec (repeat parallelism 1)))
to (async/chan parallelism)
work (async/pipeline parallelism
to
(map (fn [_]
(loop [i (int 0)
n (int chunk-size)]
(if (pos? n)
(recur (unchecked-inc i) (unchecked-dec n))
i))))
from
true)]
(do
(async/<!! work)
(async/<!!
(async/reduce + 0 to)))))
Evaluation count : 42 in 6 samples of 7 calls.
Execution time mean : 15,824584 ms
Execution time std-deviation : 189,562450 µs
Execution time lower quantile : 15,691798 ms ( 2,5%)
Execution time upper quantile : 16,145688 ms (97,5%)
Overhead used : 1,808581 ns
Found 1 outliers in 6 samples (16,6667 %)
low-severe 1 (16,6667 %)
Variance from outliers : 13,8889 % Variance is moderately inflated by outliers
=> nil
pmap(criterium/quick-bench
(reduce + (let [limit (int 1e8)
parallelism 100
chunk-size (int (/ limit parallelism))]
(pmap (fn [_]
(loop [i (int 0)
n (int chunk-size)]
(if (pos? n)
(recur (unchecked-inc i) (unchecked-dec n))
i)))
(range parallelism)))))
Evaluation count : 42 in 6 samples of 7 calls.
Execution time mean : 15,587236 ms
Execution time std-deviation : 253,629665 µs
Execution time lower quantile : 15,394598 ms ( 2,5%)
Execution time upper quantile : 16,013861 ms (97,5%)
Overhead used : 1,808581 ns
Found 1 outliers in 6 samples (16,6667 %)
low-severe 1 (16,6667 %)
Variance from outliers : 13,8889 % Variance is moderately inflated by outliers
=> nil
ST
(time
(let [limit (int 1e8)
parallelism 100
chunk-size (int (/ limit parallelism))
coll (vec (repeat limit 1))]
(time
(r/fold chunk-size
(fn
([] 0)
([i x] (+ i x)))
(fn
([] 0)
([i _] (unchecked-inc i)))
coll))))
"Elapsed time: 1337.647 msecs"
"Elapsed time: 2510.5126 msecs"
=> 100000000
DF
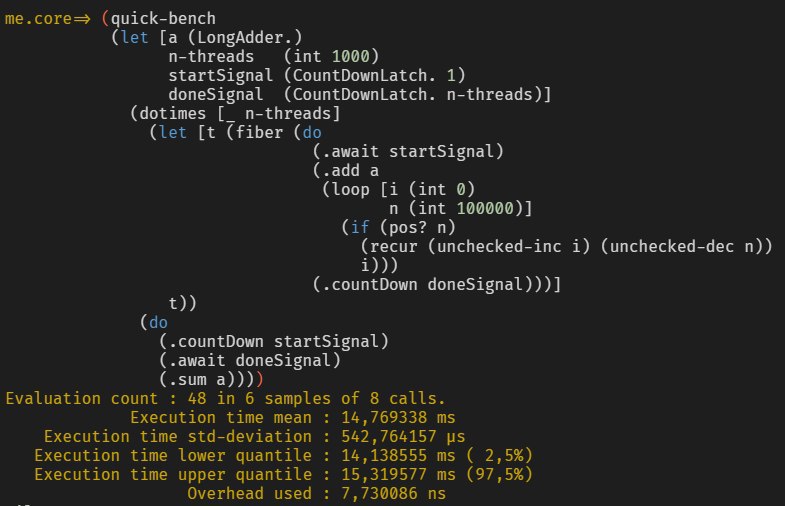
DF
A
ST
(criterium/quick-bench
(let [limit (int 1e8)
parallelism 100
chunk-size (int (/ limit parallelism))
from (async/to-chan
(repeat parallelism (fn []
(loop [i (int 0)
n (int chunk-size)]
(if (pos? n)
(recur (unchecked-inc i) (unchecked-dec n))
i)))))
to (async/chan parallelism)
work (async/pipeline parallelism to (map #(%)) from true)]
(async/<!! work)
(async/<!!
(async/reduce + 0 to))))
Evaluation count : 60 in 6 samples of 10 calls.
Execution time mean : 10,729943 ms
Execution time std-deviation : 141,940603 µs
Execution time lower quantile : 10,572088 ms ( 2,5%)
Execution time upper quantile : 10,929712 ms (97,5%)
Overhead used : 1,827556 ns
=> nil
(criterium/quick-bench
(reduce + (let [limit (int 1e8)
parallelism 100
chunk-size (int (/ limit parallelism))]
(pmap #(%)
(repeat parallelism (fn []
(loop [i (int 0)
n (int chunk-size)]
(if (pos? n)
(recur (unchecked-inc i) (unchecked-dec n))
i))))))))
Evaluation count : 60 in 6 samples of 10 calls.
Execution time mean : 10,509147 ms
Execution time std-deviation : 113,948602 µs
Execution time lower quantile : 10,376058 ms ( 2,5%)
Execution time upper quantile : 10,631008 ms (97,5%)
Overhead used : 1,827556 ns
=> nil
IP
ST
DF
ST

