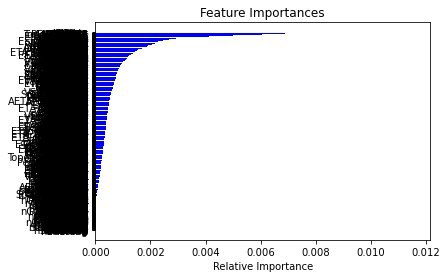
features = X.columns importances = rnd_clf.feature_importances_ indices = np.argsort(importances)
plt.title('Feature Importances') plt.barh(range(len(indices)), importances[indices], color='b', align='center') plt.yticks(range(len(indices)), [features[i] for i in indices]) plt.xlabel('Relative Importance') plt.show()
Народ, а никто случайно не встречал подходов для предсказания time-series в верхнюю сторону? То есть чтобы сетка предсказывала значение как можно ближе, но предсказанное значение должно быть обязательно больше актуального. Если использовать tf.where в лоссе, ломается градиент. И шаманство с tf.stop_gradient не особо помогает. Reinforcement learning очень не хочется использовать
Народ, а никто случайно не встречал подходов для предсказания time-series в верхнюю сторону? То есть чтобы сетка предсказывала значение как можно ближе, но предсказанное значение должно быть обязательно больше актуального. Если использовать tf.where в лоссе, ломается градиент. И шаманство с tf.stop_gradient не особо помогает. Reinforcement learning очень не хочется использовать
Чтобы "обязательно больше", такого - не видел. Но можно обучить квантильную регрессию (и для бустинга, и для сеток соответствующий лосс есть или легко закодить), тогда модель будет пытаться накрыть сверху, скажем, 99% значений.
Можешь считать это гладкой аппроксимацией твоего where, кстати.
Всем добрый день. Есть датафрейм. В одно из его столбцов "text" хранится текст. Нужно создать доп столбец в котором будет хранится длина этого текста. Т.е. к примеру в 5й строке в столбце "text" хранится "привет". Нужно в новый столбик в этой строке занести число 6. Можно ли это сделать без цикла?
Дата-сайентисты из Контура, Вконтакте и Одноклассников соскучились по встречам с единомышленниками и приготовили онлайн-митап, который нельзя пропустить.
В программе: ✔️Воспроизведение — это не мучение! Михаил Марюфич (Одноклассники) ✔️Как в ВКонтакте деплоят нейросети в продакшн. Дмитрий Юткин (Вконтакте) ✔️Быстрый и предсказуемый процесс деплоя моделей в продакшн. Никита Тарасов (Контур)