Недавно публиковал у себя на странице Facebook новость про инкрементное обновление кастомных коннекторов в Power BI (таких как Яндекс.Директ, Google Analytics и подобных).
Если кратко - теперь не надо каждый раз тянуть данные за несколько месяцев или лет. Можно дополнять отчёт данными за пару последних дней или недель.
Как этого добиться?
1) Создайте ограниченный динамическими датами запрос (например от 2daysAgo до yesterday).
2) Создайте 2 параметра - RangeStart и RangeEnd формата Дата + время. Неважно чему они будут равны в Power BI Desktop.
3) Зафильтруйте дату в запросе 2 созданными параметрами - Дата больше равна RangeStart И меньше RangeEnd.
4) Выгрузите результат в модель. Установите на табличку добавочное обновление - за сколько дней хотите обновлять её. Если один - будет обновляться за сегодня, если два - сегодня и вчера, итд.
Если запрос начинается с yesterday, то лучше всего ставить 1 день, если начинается с 2daysAgo, то ставим 2 дня, итд. Иначе он попытается получить данные за более ранний период, вытянет нулевое значение и оставит его в базе, а это нам не надо.
5) Выгрузите всё это в Power BI Service и установите расписание обновлений.
Как это работает:
Запрос всегда идёт в рамках дат, указанных в коннекторе (например от 2daysAgo до today). Но из-за добавочного обновления Power BI Service забирает только нужные ему даты и плюсует их к остальным данным. В итоге мы можем не тянуть статистику за весь период.
Если API в какой-то момент накосячит, например за 15 марта, то в отчёте останутся неправильные данные. Чтобы это исправить, рекомендую иметь отдельный необновляемый запрос с фиксированными датами за более ранний период. Например, запрос за январь-февраль 2021. Когда вы видите ошибку за 15-е марта 2021, вы добавляете в этот запрос половину марта, перетягивая ошибочные данные. И снова запускаете инкремент по новым датам. Я думаю ошибки будут очень редкими, но они бывают в любом API.
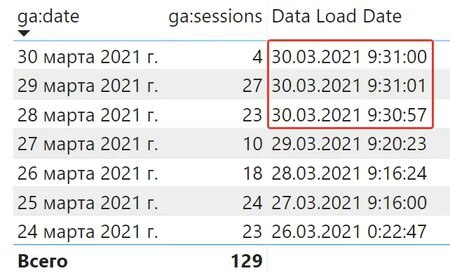
Мой запрос на скрине тянет последние пару дней, а статистика уже накопилась за неделю;)
https://yadi.sk/i/YIWXNbYGtXZrJg