JJ
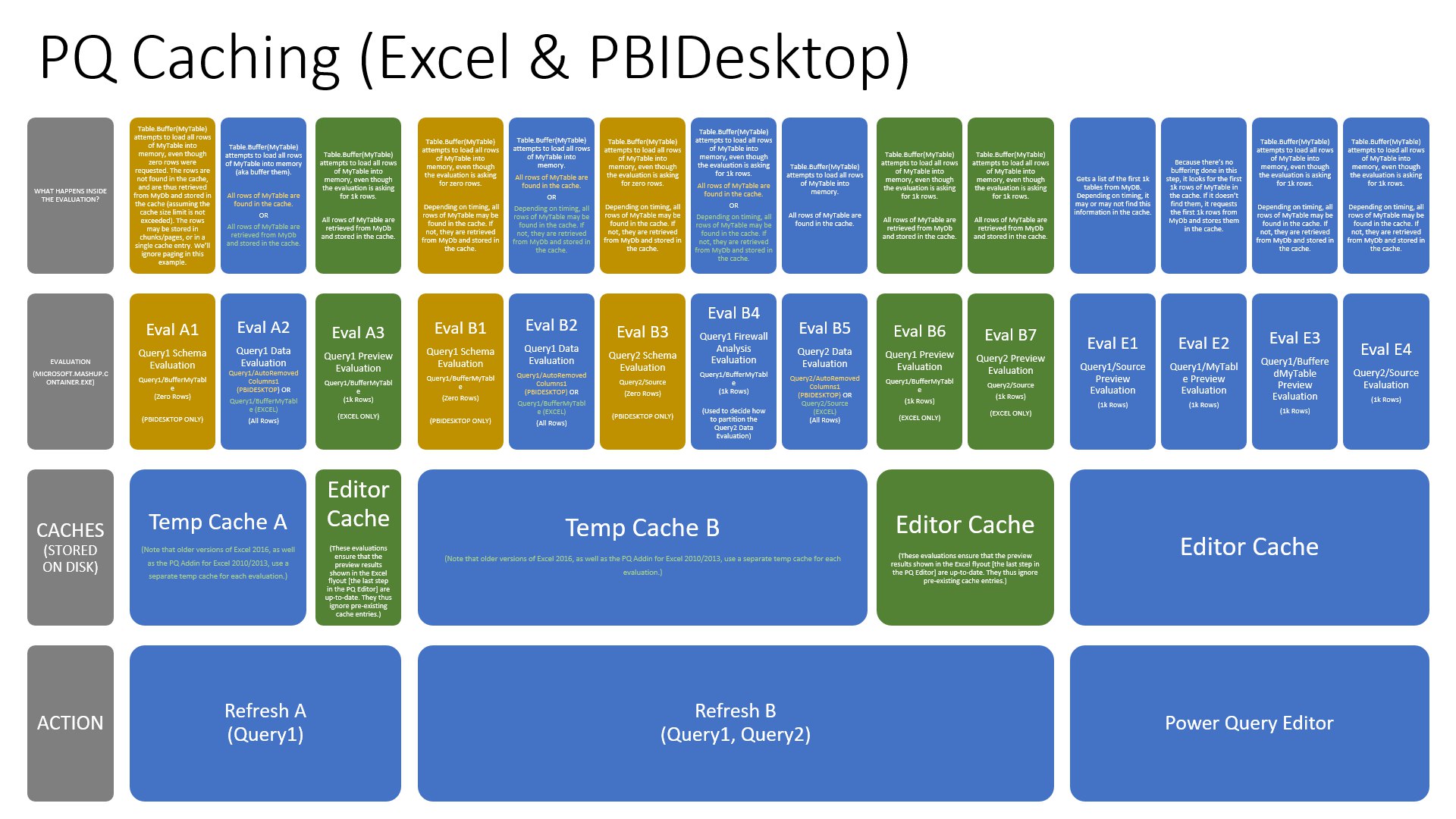
продолжение тестов, пока матчасть пытаюсь понять. я поставила буфер в предыдущем запросе, который мерджу к последнему, и из которого потребности попадают в подтаблицу. в том запросе считаются потребности нарастающим итогом по датам. сам запрос качал 250 МБ из того же файлика 10МБ (что гораздо меньше и намного быстрее, чем последний запрос с 2Гб), отрабатывал максимум за минуту, поэтому я его в приоритет не ставила, а начала искать возможности оптимизации последнего запроса, работающего больше получаса и качающего 2Гб. поставила буфер на шаге перед расчетом нарастающего итога. В результате последний запрос стал тоже обновляться намного быстрее, всего несколько минут. то есть надо понять точку максимальной эффективности приложения усилий правильно, и тогда результат сразу на лицо.